









|
|
|
|
|
|
|
|
|
|
|
version 11
Overview
In databases created with version 11 of 4D, the language as well as the database engine store and work natively with Unicode characters.
This facilitates the internationalization of 4D applications. Unicode is a standard unified character set that can handle practically every common language of the world. A character set is a character/number value correspondence table, for example "a"->1, "b"->2, "5"->15, "oe"->662, and so on. Whereas with ASCII, the basic number value is typically included between 1 and 127, with Unicode the upper limit exceeds 65,000, which means that nearly every character for all languages can be represented.
There are several ways to code the Unicode number values: UTF-16 codes them on 16-bit integers, UTF-32 uses 32-bit integers and UTF-8 uses 8-bit integers. 4D mainly uses UTF-16 (like Windows and Mac OS). Sometimes, essentially for specific needs related to the Internet, 4D uses UTF-8 which has the advantage of being more compact and having better readability for common characters (a-z,0-9).
Warning: In Unicode in 4D v11, the following character codes are reserved and must never be included in a text:
| 0 | |
| 65534 (FFFE) | |
| 65535 (FFFF) |
ASCII Compatibility Mode
Previous versions of 4D worked with the extended ASCII table of Macintosh (see the ASCII Codes section). By default, databases converted from a previous version of 4D continue to function in this mode called "ASCII compatibility mode".
It is possible to apply the Unicode mode to converted databases via the Unicode Mode selector of the Get database parameter and SET DATABASE PARAMETER commands or via the Unicode Mode option found on the Application/Compatibility page of the Preferences:
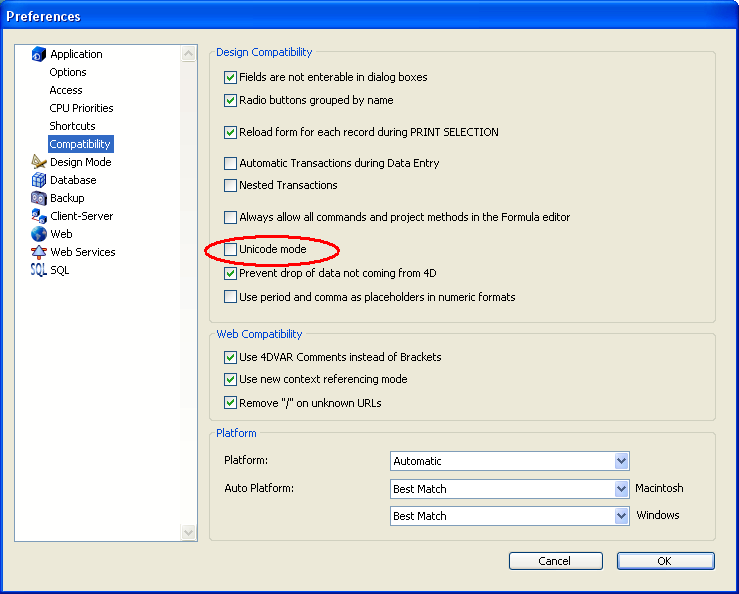
Note: This mode is specific to each database. It is therefore possible to have a Unicode database coexisting with non-Unicode components (or vice versa).
In most cases, the initial functioning of applications is not affected by this setting, since 4D handles any necessary character conversions internally. Moreoever, the most common characters (a-z, 0-9, and so on) have the same value (from1 to 127) in both Unicode and ASCII (Windows and Mac OS).
However, certain language statements, more particularly those using commands that work with character strings, may require some adaptation. For example, the statement Char(200) will not return the same value in Unicode as in ASCII. This manual describes the differences in functioning between the Unicode mode and the ASCII compatibility mode for each command concerned.
|
|
|
|
|
|
|
|
|
|
|