



I. Introduction▲
Cette note technique est la première d’une série de deux, ayant pour objectif la réalisation d’un client UDDI mettant à l’œuvre les fonctionnalités de client de service Web natives dans 4D 2003.
UDDI (Universal Description, Discovery and Integration) est un protocole fondé sur SOAP. Cette note technique suppose donc que le lecteur est déjà familier avec SOAP, les services Web et XML. Le processus d’utilisation du client de service Web et des nouvelles commandes d’analyse XML de 4D sera détaillé.
Un client UDDI peut s’utiliser de deux façons, en invoquant un service Web :
· de recherche, effectuant une requête auprès d’un serveur UDDI ;
· d’enregistrement, en vue de publier un service Web sur un serveur UDDI.
Cette première note technique s’attachera à l’aspect requête tandis que la seconde détaillera la publication d’un service Web.
La base de démo est loin d’inclure toutes les fonctionnalités d’un client UDDI, mais elle représente un très bon point de départ de l’ implémentation d’un client UDDI.
La base de démo accompagnant cette note ne propose pas de fonction de publication, la seconde base sera fournie avec une prochaine note technique et inclura les deux aspects de recherche et publication.
II. Survol rapide d’UDDI▲
Une page HTML peut se retrouver perdue dans l’anonymat de billions d’autres pages sur le Web. Quelques pionniers du Web des années 80 émirent l’idée de créer des annuaires, de manière à procurer aux autres utilisateurs du Web un moyen simplifié de trouver rapidement n’importe quel page sur n’importe quel sujet. Avec l’avènement des services Web, quelques sites Web (comme xmethods.net) ont commencé à fournir un service d’enregistrement. Dans une approche analogue à celle de Yahoo, les fournisseurs de services Web doivent enregistrer leurs services de façon à les publier pour les rendre accessibles au public.
UDDI propose le même genre d’outil de recherche, mais bâti sur le protocole SOAP. Il devient ainsi possible de requêter la base de données UDDI depuis n’importe quel langage supportant le protocole SOAP et d’intégrer dans la même application, les services Web et les fonctions de recherche au lieu de devoir passer par un navigateur.
Fourni avec 4D 2003, le client SOAP permet aux utilisateurs d’effectuer des requêtes sur un tel type de serveur. Il devient ainsi possible de trouver et utiliser un service Web, disponible sur Internet si les requêtes sont envoyées vers un serveur UDDI sur le Web ou sur n’importe quel réseau interne pourvu que celui-ci héberge un serveur UDDI centralisant tous les services Web disponibles en interne.
La définition d’UDDI a d’abord été l’affaire d’un comité constitué par les rédacteurs des spécifications SOAP. Les spécifications UDDI sont maintenant entre les mains d’OASIS, une association essayant de regrouper toutes les spécifications de protocoles liés à XML avant de les soumettre au W3C (se référer à www.oasisopen. org).
UDDI en est aujourd’hui à la troisième version de ses spécifications et quelques organisations proposent déjà des serveurs auxquels vous pouvez envoyer des requêtes (XMethods, Microsoft, IBM). Sur le site Web de l’O ASIS, vous trouverez le WSDL « générique » qui n’est cependant pas un WSDL valide de service UDDI. Un WSD L DOIT (d’après les spécifications) comporter un élément « service » qui a pour fonction d’agréger une série de ports reliés (correspondant à une collection de points finaux du réseau). Comme le WSDL fourni sur OASIS est défini comme « générique », il ne comprend pas d’élément service, car il n’est lié à aucun serveur spécifique. En con séquence vous ne pouvez pas analyser le WSDL UDDI générique à l’aide de l’assistant de service Web de 4D ou de n’importe quel analyseur de WSDL. En revanche, ce WSDL est très utile, car il spécifie un cadre d’échange de données entre les clients et les serveurs UDDI. Il liste les méthodes qui devraient être proposées par un serveur UDDI accompagnées pour chacune d’entre elles de ses paramètres et valeurs de retour.
Dans cette note technique, nous allons nous cantonner aux API d’interrogation qui permettent à un client UDDI de rechercher des services Web sur des serveurs UDDI. Le WSDL attaché à ce service d’interrogation se trouve ici :
III. Présentation d’UDDI▲
UDDI est un protocole s’appuyant sur SOAP, les couches peuvent se représenter ainsi :
· UDDI
· SOAP
· XML
· Protocole de transport Internet (HTTP, TCP/IP)
La spécification UDDI décrit un nuage conceptuel (centralisation logique d’un ensemble de nœuds physiques d’opérateurs) de services Web et une interface de programmation qui définit un canevas relativement simple permettant de décrire tout type de service Web. La spécification comprend plusieurs documents reliés et un schéma XML qui définit un protocole de programmation fondé sur SOAP pour enregistrer et découvrir les services Web.
IV. Survol technique▲
Les spécifications UDDI consistent en un schéma XML pour les messages SOAP et une spécification des API UDDI. L’ensemble procure un modèle d’information de base et un cadre d’interaction offrant la capacité de publier et retrouver de l’information sur un large spectre de services Web.
V. Quatre types d’information▲
Le cœur du modèle d’information utilisé par les registres UDDI est défini par un schéma XML. Le choix de XML se justifie par sa neutralité vis-à-vis des plateformes et sa capacité à décrire de manière naturelle les relations hiérarchiques. Le standard émergent XML Schéma a été choisi pour son support de types de données complexes et sa capacité à décrire facilement des modèles d’information.
Le schéma XML UDDI définit quatre types d’informations de base représentant les données nécessaires à un technicien désireux d’utiliser les services Web d’un partenaire :
· Information métier (business information) ;
· Information service (service information) ;
· Information de liaison (binding information) ;
· Information sur les spécifications des services.
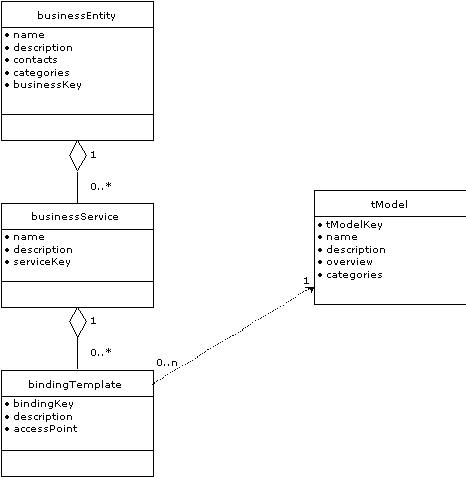
Information métier : l’élément businessEntity
Ce modèle sert à stocker toutes les informations sur une entreprise qui publie des informations, sur ses contacts et les services proposés. Elle stocke également une clé unique, identifiant l’entité commerciale : UUID (Universal Unique Identifier). Correspond aux pages blanches de l’annuaire.
Information service : l’élément businessService
Ces informations consistent en la description métier des services Web; deux structures sont définies : businessService et bindingTemplate. Une structure businessEntity peut contenir plusieurs structures businessService.
La structure businessService est un conteneur descriptif utilisé pour regrouper des séries de services Web reliés par le processus métier ou la catégorie de services. On pourrait citer comme exemples de processus métiers pouvant se décliner en service Web : les services achats, les services d’expédition et d’autres processus métier de haut-niveau. Correspond aux pages jaunes de l’annuaire.
Information de liaison : l’élément bindingTemplate
Les détails techniques requis pour interroger physiquement un service sont décrits dans des structures bindingTemplate. Ces structures sont également appelées pages vertes. Elles gèrent la liste des structures tModels que nous retrouverons dans la suite de cette note.
Pointeurs de spécifications et empreintes techniques (technical fingerprints)
Le bindingTemplate ne se révèle pas toujours suffisant pour simplement savoir où contacter un service Web particulier, il décrit généralement le service en donnant son URL et une référence vers un élément tModel. Cette structure comprend des informations propres à l’utilisation du service Web, comprenant son nom, l’identité de l’organisation qui publie et des pointeurs URL vers la description physique (formats de données, protocoles de transport), habituellement sous forme de WSDL.
VI. Les API de programmation▲
Les spécifications de UDDI comprennent la description d’interfaces de service Web permettant un accès par programmation à l’information contenue dans le registre UDDI. Cette API se divise en deux parties logiques : les API d’interrogation (sur lesquelles nous allons nous focaliser dans la suite de cette note technique); les API de publication (qui seront abordées dans la seconde note).
Les API d’interrogation se découpent elles-mêmes en deux sous-parties :
· une première utilisée pour construire des programmes qui interrogent et parcourent l’annuaire UDDI;
· une seconde utile dans l’éventualité où l’interrogation du service échoue.
La suite de cette note se restreindra sur la première de ces deux sous-parties : rechercher et naviguer dans l’information proposée par les registres UDDI.
VII. Fondé sur SOAP▲
SOAP (Simple Object Access Protocol) est une recommandation du W3C décrivant une utilisation de XML au-dessus de HTTP afin de disposer de mécanismes d’échanges de données et d’appels de procédures distantes.
Tous les appels aux API définis par les spécifications UDDI se comportent de manière synchrone avec les registres des sites des opérateurs composant le nuage de service distribué UDDI .
VIII. Les API d’interrogation▲
Les API d’interrogation consistent en deux types d’appels qui permettent d’abord à un programme de trouver rapidement les métiers, services Web et spécifications correspondant à sa recherche, puis de rentrer dans le détail en se basant sur l’information générale procurée par les appels initiaux.
Les commandes API find_xx sont destinées aux recherches générales fondées sur de nombreux critères. Les appels directs get_xx API offrent un accès à de l’information détaillée sur un enregistrement particulier.
IX. Le modèle d’invocation UDDI▲
Chaque service Web référencé est représenté par une structure bindingTemplate. L’invocation d’un service Web s’effectue généralement sur la base d’informations fournies par une structure bindingTemplate mise au préalable en cache. Le scénario d’utilisation d’UDDI afin de rédiger un programme d’appel d’un service Web spécifique se présente alors de la manière suivante :
Le développeur utilise l’annuaire professionnel UDDI pour retrouver l’information enregistrée sur l’entreprise ou sur le partenaire qui déclare le service Web : information businessEntity.
Le développeur rentre au choix plus en détail dans une structure businessService ou demande une structure complète businessEntity, puis sélectionne un bindingTemplate particulier.
En se basant sur le bindingTemplate, le développeur obtient de l’information sur les spécifications du service Web au travers des structures tModel référencées par une clé unique contenue dans l’attribut tModelKey. Dans le cas de 4D, une fois connu le lien vers le WSDL, le recours à l’assistant de web service permet de « découvrir » le service Web.
En général, les appels au service distant fonctionneront correctement, les cas particuliers d’échecs et les moyens d’y faire face sont explicités ci-dessous.
X. Faire face à un échec lors de l’appel d’un service Web▲
L’un des principaux bénéfices à maintenir de l’information sur les services Web dans un annuaire UDDI distribué réside dans l’aspect « self service » fourni aux techniciens. Les entreprises utilisant les services Web dans des opérations commerciales avec leurs partenaires doivent être capables de détecter et de gérer les problèmes de communication ou les autres causes d’échec. L’un des principaux soucis consiste dans la capacité de prédire, détecter, ou réparer les échecs dans les systèmes d’un partenaire distant. De simples situations d’interruptions temporaires provoquées par de la maintenance ou des sauvegardes nocturnes peuvent freiner la décision de migrer vers les services Web. D’un autre côté, si vous êtes l’entreprise qui fournit les connexions directes aux services Web, la remise en route après une panne et la capacité de basculer totalement sur un système de sauvegarde sont des préoccupations primordiales. Je n’aborderai pas cet aspect dans cette note technique quoique cela puisse représenter le sujet d’une autre note si plusieurs développeurs sont intéressés…