








|
|
|
|
|
|
|
|
|
|
|
Version 11 (Geändert)
Mengen sind ein leistungsstarkes und flinkes Werkzeug zum Bearbeiten von Datensatzauswahlen. Sie können Mengen erstellen, speichern, laden und löschen, sowie der aktuellen Auswahl zuordnen. Mit 4D können Sie außerdem folgende Standardmengen bilden:
• Schnittmenge
• Vereinigungsmenge
• Differenzmenge
Mengen und die aktuelle Auswahl
Eine Menge ist die kompakte Darstellung einer aktuellen Auswahl. Menge und Auswahlen haben gewisse Ähnlichkeiten. Eine Menge ist eine boolesche Tabelle, die ausgewählte Datensätze durch 1 bzw. nicht ausgewählte durch 0 anzeigt.
Benutzen Sie Mengen hauptsächlich dann, wenn Sie:
• Im gleichen Prozess mit mehreren Auswahlen arbeiten.
• Die Auswahl kurzfristig sichern und dann wiederherstellen möchten.
• Auf eine vom Benutzer angeklickte Teilauswahl zugreifen möchten
(Menge UserSet).
• Aus zwei Auswahlen die Vereinigungs-, Schnitt- oder Differenzmenge bilden möchten.
Sie können sich die aktuelle Auswahl als eine Liste oder Tabelle, die auf jeden Datensatz der Auswahl zeigt, vorstellen. In dieser Liste sind nur die Datensätze der aktuellen Auswahl aufgeführt. Die aktuelle Auswahl enthält nicht die Datensätze selbst, sondern nur die Zeiger auf ihre Adressen. Jeder Zeiger auf einen Datensatz belegt im Speicher 32 Bits oder 4 Bytes. Arbeiten Sie in einer Tabelle, arbeiten Sie immer mit einer aktuellen Auswahl. Sortieren Sie die aktuelle Auswahl, sortieren Sie in Wirklichkeit nur die Zeiger. Es gibt in jedem Prozess nur eine aktuelle Auswahl pro Tabelle.
Eine Menge ist die Beschreibung einer Auswahl. Jeder Datensatz wird mit einem Bit (1/8 eines Byte) dargestellt: Dieses Bit enthält die Ziffer 1 für die ausgewählten und die Ziffer 0 für die nicht ausgewählten Datensätze. Das Arbeiten mit Mengen ist daher sehr schnell. 4D muss nur wenige Informationen verarbeiten.
Die Größe einer Menge in Bits entspricht immer der Anzahl der Datensätze der Tabelle. Erzeugen Sie beispielsweise eine Menge aus einer Tabelle mit 10 000 Datensätzen, umfasst die Menge 10 000 Bits bzw. 1 250 Bytes oder 1,2 KB im RAM.
Für eine Tabelle können Sie beliebig viele Mengen erzeugen.
Mengen lassen sich unabhängig von der Datenbank auf der Festplatte speichern. Wollen Sie einen Datensatz ändern, der zu einer Menge gehört, müssen Sie die Menge zuerst zur aktuellen Auswahl machen. Hier können Sie dann einen oder mehrere Datensätze ändern.
Eine Menge ist nie sortiert, da sie nur die Information enthält, ob der Datensatz enthalten oder nicht enthalten ist. Im Gegensatz dazu ist eine temporäre Auswahl sortiert, sie benötigt jedoch in den meisten Fällen mehr Speicher. Weitere Informationen dazu finden Sie im Abschnitt Temporäre Auswahl.
Eine Menge merkt sich, welcher Datensatz beim Erstellen der Menge der aktuelle Datensatz war. Folgende Tabelle zeigt die Unterschiede zwischen der aktuellen Auswahl und der Menge:
Vergleichskriterium Temporäre Auswahl Menge
| Anzahl pro Tabelle und Prozess | 1 | Beliebig |
| Sortieren | Ja | Nein |
| Sichern auf Festplatte | Nein | Ja |
| RAM pro Datensatz | (4 Bytes) pro ausge- | 1 Bit (1/8 Byte) pro vor- |
| wähltem Datensatz | handenem Datensatz | |
| Kombinierbar | Nein | Ja |
| Rechenoperationen | Nein | Ja |
| Enthält aktuellen Datensatz | Ja | Ja, beim Erzeugen der Menge |
Eine Menge bezieht sich immer auf die Tabelle, für die sie erzeugt wurde. Bei Operationen mit mehreren Mengen, wie Schnitt- oder Vereinigungsmengen, müssen alle Mengen der gleichen Tabelle angehören.
Mengen sind von den Datensätzen abhängig. Nach einer Änderung in der aktuellen Auswahl kann die Menge veraltet sein, vor allem beim Anlegen bzw. Löschen von Datensätzen.
Nehmen Sie beispielsweise eine Auswahl mit allen Einwohnern von Köln. Sie legen davon eine Menge an. Zieht nun ein Einwohner weg, ist die Menge nicht mehr gültig. Sie repräsentiert nicht mehr die Einwohner von Köln. Eine Menge beschreibt nur die aktuelle Auswahl zu einem bestimmten Zeitpunkt. Wird der Inhalt der Datensätze verändert oder werden Datensätze in der aktuellen Auswahl gelöscht bzw. hinzugefügt, stellt die Menge nicht mehr die aktuelle Auswahl dar.
Typen von Mengen
Es gibt folgende Arten:
• Prozessmenge: Sie gilt nur für den Prozess, in dem sie erzeugt wurde. Sie benötigt keine spezielle Vorsilbe im Namen und wird gelöscht, sobald die Prozessmethode endet. UserSet und LockedSet sind auch Prozessmengen.
• Interprozessmenge: Sie gilt für alle Prozesse der Arbeitsstation. Der Interprozessmenge werden die Zeichen "kleiner als, größer als" (<>) vorangestellt. Diese Syntax gilt sowohl für Windows als auch für Macintosh. Auf Macintosh können Sie auch das Zeichen <> benutzen. Sie erhalten es mit der Kombination Wahl- + Umschalttaste + Buchstabe v).
Eine Interprozessmenge ist für alle Prozesse der Datenbank sichtbar.
Im Client/Server-Betrieb ist sie für alle Prozesse jedes Clients sichtbar, wenn sie in einem Client Prozess erstellt wurde; oder für alle Server Prozesse, wenn sie in einem Serverprozess (stored procedure) erstellt wurde.
Ihr Name muss in der Datenbank einmalig sein.
• Lokale Mengen/Client Mengen: Lokale bzw. Client Mengen dienen zur Verwendung im Client/Server-Modus. Version 6 führt lokale bzw. Client Mengen ein. Diesen Mengen wird das Dollarzeichen ($) vorangestellt. Sie werden im Gegensatz zu anderen Mengen auf dem Client-Rechner gespeichert.
Weitere Informationen dazu finden Sie im Handbuch 4D Server Administration im Abschnitt 4D Server und Mengen.
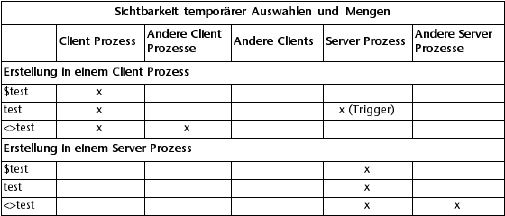
Sichtbarkeit von Mengen
Nachfolgende Tabelle zeigt, wie temporäre Auswahlen sichtbar sind, je nachdem, wo sie erstellt wurden:
Menge und Transaktion
Eine Menge können Sie auch während einer Transaktion erzeugen. Sie kann aus den Datensätzen bestehen, die während der Transaktion erzeugt wurden oder aus Datensätzen, die schon angelegt waren. Nach Verlassen der Transaktion sollten Sie diese Menge löschen, da sie ungültig wird. Datensätze, die in einer Transaktion angelegt werden, erhalten vorläufige Datensatznummern ab 18 000 000. Nach der Bestätigung werden ihnen neue Nummern zugewiesen. Die während der Transaktion erzeugte Menge findet dann diese vorläufigen Datensatznummern nicht mehr.
Beispiel
Folgendes Beispiel löscht doppelte Datensätze aus der Tabelle [People]. Eine Schleife For...End for durchläuft alle Datensätze und vergleicht den aktuellen Datensatz mit dem vorigen. Sind Name, Straße und Postleitzahl gleich, wird der Datensatz in die Menge gelegt. Am Ende der Schleife wird diese Menge die aktuelle Auswahl, die alte aktuelle Auswahl wird gelöscht:
CREATE EMPTY SET([People];"Duplikate")
` Erstelle leere Menge für doppelte Datensätze
ALL RECORDS([People])
` Wähle alle Datensätze aus
` Sortiere Datensätze nach PLZ, Straße, Name etc.
` so daß die doppelten aufeinander folgen
ORDER BY ([People];[People]PLZ;>;[People]Address;>;[People]Name;>)
` Initialisiere Variablen mit den Feldern des vorigen Datensatzes
$Name:=[People]Name
$Address:=[People]Address
$PLZ:=[People]PLZ
` Gehe zum zweiten Datensatz, um ihn mit dem ersten zu vergleichen
NEXT RECORD ([People])
For ($i; 2; Records in table ([People]))
` Durchlaufe Datensätze beginnend mit 2
` Sind Name, Straße und PLZ gleich mit dem vorigen Datensatz,
` ist es ein doppelter Datensatz.
If (([People]Name=$Name) & ([People]Address=$Address) & ([People]PLZ=$PLZ))
` Füge aktuellen Datensatz (den doppelten) hinzu
ADD TO SET ([People]; "Duplikate")
Else
` Sichere Name, Straße und PLZ dieses Datensatzes
` zum Vergleichen mit dem nächsten Datensatz
$Name:=[People]Name
$Address:=[People]Address
$ZIP:=[People]PLZ
End if
` Gehe zum nächsten Datensatz
NEXT RECORD ([People])
End for
` Verwende gefundene doppelte Datensätze
USE SET ("Duplikate")
` Lösche doppelte Datensätze
DELETE SELECTION ([People])
` Entferne die Menge aus dem Speicher
CLEAR SET ("Duplikate")
Alternativ dazu können Sie am Ende der Methode die Datensätze auch zuerst auf dem Bildschirm anzeigen oder ausdrucken, um so einen genaueren Vergleich auszuführen.
Die Systemmenge UserSet
4D erzeugt automatisch die Menge UserSet. Sie enthält die Datensätze, die der Anwender in einer mit MODIFY SELECTION oder DISPLAY SELECTION erzeugten Liste angeklickt hat.
4D Server: Die Systemmenge UserSet ist lokal, auch wenn ihr Name nicht mit dem Dollarzeichen ($) beginnt. Stellen Sie deshalb beim Aufrufen von INTERSECTION, UNION und DIFFERENCE sicher, dass UserSet nur mit lokalen Mengen genutzt wird. Weitere Informationen dazu finden Sie in der Beschreibung dieser Befehle und im Handbuch 4D Server Administration im Kapitel 4D Server und Mengen.
Eine Tabelle hat keine eigene Menge UserSet. UserSet gilt für alle Tabellen der Datenbank. Es gibt also auch nur eine Menge UserSet pro Prozess.
4D verwaltet die Menge UserSet für Listenformulare, die im Designmodus oder über die Befehle MODIFY SELECTION bzw. DISPLAY SELECTION angezeigt werden. Diese Funktionsweise ist jedoch nicht für Unterformulare aktiv.
Folgende Methode zeigt Datensätze an, lässt den Benutzer einige auswählen und zeigt dann die ausgewählten Datensätze in UserSet an:
` Zeige alle Datensätze und lass den Benutzer eine beliebige Anzahl auswählen.
` Zeige diese Auswahl in UserSet, um die aktuelle Auswahl zu ändern.
OUTPUT FORM ([People]; "Display") ` Setze Ausgabeformular
ALL RECORDS ([People]) ` Wähle alle Personen
ALERT ("Wähle die gewünschten Personen mit der Kombination Ctrl- bzw.
Befehlstaste und Klick.")
DISPLAY SELECTION ([People]) ` Zeige die Personen
USE SET ("UserSet") ` Verwende die ausgewählten Personen
ALERT ("Sie haben folgende Personen gewählt.")
DISPLAY SELECTION ([People]) ` Zeige die ausgewählten Personen
Hinweis: Um UserSet wiederzufinden, müssen Sie MODIFY SELECTION oder DISPLAY SELECTION ausführen.
Die Systemmenge LockedSet
Die Befehle APPLY TO SELECTION, ARRAY TO SELECTION und DELETE SELECTION erzeugen in der Multiprozess-Umgebung automatisch die Menge LockedSet. Auch Suchbefehle erstellen eine solche Menge, wenn sie im Kontext "Suchen und Sperren" gesperrte Datensätze finden (siehe Befehl SET QUERY AND LOCK). LockedSet enthält die Datensätze, die beim Ausführen des Befehls gesperrt waren.
Referenz
|
|
|
|
|
|
|
|
|
|
|