








|
|
|
|
|
|
|
|
|
|
|
Version 11.2 (Geändert)
Ein Trigger ist eine Methode, die einer Tabelle zugeordnet ist. Er ist eine Tabelleneigenschaft. Sie rufen Trigger nicht auf; die Engine der 4D Datenbank ruft sie automatisch auf, wenn Sie Datensätze der Tabelle bearbeiten, also Datensätze hinzufügen, löschen, ändern und laden. Sie können ganz einfache Trigger schreiben und sie dann komplexer machen.
Trigger sind ein leistungsstarkes Werkzeug, denn sie unterbinden "illegale" Operationen auf Datensätze Ihrer Datenbank. Sie lassen nur bestimmte Operationen für eine Tabelle zu und verhindern, dass Daten versehentlich verloren gehen oder beschädigt werden. Ein Trigger sorgt zum Beispiel in einem Rechnungssystem dafür, dass der Benutzer eine Rechnung nur hinzufügen kann, wenn er auch den Kunden einträgt, an den die Rechnung gestellt wird.
Trigger aktivieren und einstellen
Erstellen Sie in der Designumgebung eine Tabelle, hat sie standardmäßig keinen Trigger.
Wollen Sie für eine Tabelle einen Trigger verwenden, müssen Sie:
• Den Trigger aktivieren und 4D anweisen, dass er aufgerufen werden soll.
• Den Code für den Trigger schreiben.
Aktivieren Sie einen Trigger, der noch nicht geschrieben wurde bzw. schreiben Sie einen Trigger, ohne ihn zu aktivieren, hat er keine Auswirkung auf die Operationen der Tabelle.
1. Trigger aktivieren
Wählen Sie dazu im Inspektorfenster der Struktur unter Trigger eine Option (Datenbankereignisse) für die Tabelle:
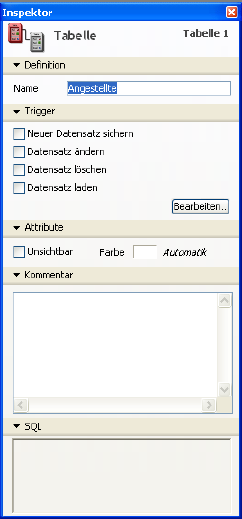
Neuer Datensatz sichern
Mit dieser Option wird der Trigger immer aufgerufen, wenn in der Tabelle ein Datensatz hinzugefügt wird.
Dieser Fall tritt ein, wenn Sie:
• Einen Datensatz in Dateneingabe hinzufügen (Designumgebung, über den Befehl ADD RECORD oder den SQL Befehl INSERT).
• Einen Datensatz mit CREATE RECORD und SAVE RECORD erstellen und sichern. Beachten Sie, dass der Trigger beim Aufrufen von SAVE RECORD und nicht beim Erstellen aktiv wird.
• Datensätze importieren (Designumgebung oder über einen Importbefehl).
• Andere Befehle aufrufen, die neue Datensätze erstellen und/oder sichern, z.B. ARRAY TO SELECTION, SAVE RELATED ONE, etc..
• Ein Plug-In einsetzen, das die Befehle CREATE RECORD und SAVE RECORD aufruft.
Datensatz ändern
Mit dieser Option wird der Trigger immer aufgerufen, wenn in der Tabelle ein Datensatz geändert wird.
Dieser Fall tritt ein, wenn Sie:
• Einen Datensatz in Dateneingabe ändern (Designumgebung, über den Befehl MODIFY RECORD oder den SQL Befehl UPDATE).
• Einen bereits vorhandenen Datensatz mit SAVE RECORD sichern.
• Andere Befehle aufrufen, die vorhandene Datensätze sichern, z.B. ARRAY TO SELECTION, APPLY TO SELECTION, MODIFY SELECTION, etc.).
• Ein Plug-In einsetzen, das den Befehl SAVE RECORD aufruft.
Datensatz löschen
Mit dieser Option wird der Trigger immer aufgerufen, wenn in der Tabelle ein Datensatz gelöscht wird.
Dieser Fall tritt ein, wenn Sie:
• Einen Datensatz löschen (Designumgebung, über DELETE RECORD, DELETE SELECTION oder den SQL Befehl DELETE).
• Eine Operation ausführen, die verknüpfte Datensätze über die Löschkontrollen einer Verknüpfung löscht.
• Ein Plug-In einsetzen, das den Befehl DELETE RECORD aufruft.
Hinweis: Der Befehl TRUNCATE TABLE ruft keinen Trigger auf!
Wichtig: Führen Sie eine Operation bzw. einen Befehl für mehrere Datensätze aus, wird der Trigger für jeden Datensatz aufgerufen. Rufen Sie zum Beispiel den Befehl APPLY TO SELECTION für eine Tabelle auf mit einer aktuellen Auswahl von 100 Datensätzen, wird der Trigger 100 Mal aufgerufen.
2. Trigger erstellen
Einen Trigger für eine Tabelle erstellen Sie entweder über das Fenster Explorer, oder Sie klicken im Inspektorfenster auf die Schaltfläche Bearbeiten oder doppelklicken bei gedrückter alt-Taste unter Windows bzw. Wahltaste auf Macintosh und auf den Tabellentitel im Strukturfenster. Weitere Informationen dazu finden Sie im Handbuch 4D Designmodus.
Datenbankereignisse
Ein Trigger kann für eines der oben beschriebenen Datenbankereignisse ausgelöst werden. Mit der Funktion Database event prüfen Sie das Ereignis innerhalb des Triggers. Diese Funktion gibt für das jeweilige Datenbankereignis eine Zahl zurück.
Sie schreiben einen Trigger mit der Struktur Case of auf das von Database event zurückgegebene Ergebnis. Sie können die Konstanten unter dem Thema Datenbankereignisse verwenden:
` Trigger für [beliebigeTabelle] C_LONGINT($0) $0:=0 ` Die Datenbankanfrage wird angenommen Case of : Database event=On Saving New Record Event) ` Führt die Aktionen aus, um einen neuen Datensatz zu sichern : (Database event=On Saving Existing Record Event) ` Führt die Aktionen aus, um einen bestehenden Datensatz zu sichern : (Database event=On Deleting Record Event) ` Führt die Aktionen aus, um einen Datensatz zu löschen : (Database event=On Loading Record Event) ` Führt die Aktionen aus, um einen Datensatz in den Speicher zu laden End case
Trigger sind Funktionen
Ein Trigger hat zwei grundlegende Ziele:
• Aktionen an einem Datensatz ausführen, bevor dieser gesichert oder gelöscht wird.
• Eine Operation der Datenbank bestätigen oder zurückweisen.
1. Aktionen ausführen
Sie verwenden einen Trigger, um damit einen Datensatz zu prägen, sobald er gesichert oder geändert wird bzw. Informationen an eine andere Tabelle weitergibt. Der folgende Programmcode prägt z.B. einen Datensatz mit der Objektmethode Zeitstempel:
` Trigger für die Tabelle [Dokumente] Case of : (Database event=On Saving New Record Event) [Dokumente]Erstellt:=Zeitstempel [Documents]Geändert:=Zeitstempel : (Database event=On Saving Existing Record Event) [Dokumente]Geändert:=Zeitstempel End case
Hinweis: Zeitstempel gibt die Anzahl Sekunden zurück, die seit einem willkürlich festgelegten Datum vergangen sind.
Haben Sie diesen Trigger geschrieben und aktiviert, spielt es keine Rolle, ob Sie einen Datensatz über Dateneingabe, Import, eine Projektmethode oder ein 4D Plug-In hinzufügen bzw. ändern. Der Trigger prägt automatisch die Felder [Dokumente]Erstellt und [Dokumente]Geändert, bevor der Datensatz auf die Festplatte geschrieben wird.
Hinweis: Dieses Beispiel wird unter dem Befehl GET DOCUMENT PROPERTIES ausführlich beschrieben.
2. Operation der Datenbank bestätigen oder zurückweisen
Um eine Datenbankoperation zu bestätigen oder zurückzuweisen, muss der Trigger im Funktionsergebnis $0 einen Trigger Fehlercode zurückgeben.
Beispiel
Wir gehen aus von einer Tabelle [Angestellte]. Dafür gilt die Regel, dass sämtliche Datensätze eine gültige Sozialversicherungsnummer enthalten müssen. Dafür weisen Sie dem Feld[Angestellte]SV Nummer die Objektmethode Gute SVNr zu. Diese überprüft die Eingaben der Sozialversicherungsnummer, wenn Sie auf die Schaltfläche Bestätigen klicken:
` Objektmethode bBestätigen If (GuteSVNr ([Angestellte]SV Nummer)) CONFIRM Else BEEP ALERT ("Gib SV Nummer ein und klicke erneut auf OK.") End if
Ist die Sozialversicherungsnummer korrekt, bestätigen Sie die Dateneingabe; ist sie falsch, erscheint eine Meldung. Sie bleiben in der Dateneingabe.
Sie können die Datensätze in [Angestellte] auch per Programmierung erstellen. Der folgende Teil eines Code ist zwar von der Programmierung her gültig, er verstößt jedoch gegen die Regel der vorigen Objektmethode:
`Auszug aus einer Projektmethode ` ... CREATE RECORD ([Angestellte]) [Angestellte]Name :="DOE" SAVE RECORD ([Angestellte]) `DB Verstoß gegen Regel! Die SV Nummer wurde nicht zugewiesen! ` ...
Mit einem Trigger für die Tabelle [Angestellte] können Sie die Regel [Angestellte]SV Nummer auf allen Ebenen der Datenbank vorschreiben. Der Trigger sieht folgendermaßen aus:
` Trigger für [Angestellte] $0:=0 $dbEvent:=Database event Case of : (($dbEvent=On Saving New Record Event) | ($dbEvent=On Saving Existing Record Event)) If (Not(GuteSVNr ([Angestellte]SV Nummer))) $0:=-15050 Else ` ... End if ` ... End case
Sobald dieser Trigger geschrieben und aktiviert ist, erzeugt die Zeile SAVE RECORD ([Angestellte]) den Fehler -15050 der Datenbank-Engine und der Datensatz wird NICHT gesichert.
Dasselbe gilt, wenn ein 4D Plug-In versucht, einen Datensatz [Angestellte] mit einer ungültigen Sozialversicherungsnummer zu sichern. Der Trigger erzeugt denselben Fehler und der Datensatz wird NICHT gesichert.
Der Trigger garantiert, dass niemand bewusst oder versehentlich eine ungültige Sozialversicherungsnummer eingeben und sichern kann. Es spielt keine Rolle, ob es ein Benutzer, ein Datenbankdesigner, ein Plug-In oder ein 4D Open Client mit 4D Server ist.
Beachten Sie, dass Sie auch ohne Trigger auf eine Tabelle beim Sichern bzw. Löschen eines Datensatzes Fehler der Datenbank-Engine erhalten können. Versuchen Sie zum Beispiel, einen Datensatz mit doppelten Wert in einem einmaligen indizierten Feld zu sichern, erhalten Sie den Fehler -9998.
Trigger, die Fehler zurückgeben, fügen demnach in Ihrer Anwendung neue Fehler der Datenbank-Engine hinzu:
• 4D verwaltet die "regulären" Fehler: Einmaliger Index, relationale Datenkontrolle, usw.
• Über Trigger verwalten Sie eigene Fehler speziell in Ihrer Anwendung.
Wichtig: Sie können einen beliebigen Wert für den Fehlercode zurückgeben. Verwenden Sie jedoch KEINE Fehlercodes, die bereits für die 4D Datenbank-Engine reserviert sind. Sie sollten Nummern zwischen -32000 und -15000 verwenden.
Trigger-Fehler auf Prozessebene behandeln Sie genauso wie Fehler der Datenbank-Engine:
• Sie können 4D das Standardfenster für Fehlermeldung anzeigen lassen, die Methode wird dann angehalten.
• Sie können eine mit ON ERR CALL eingebaute Fehlerverwaltungsmethode verwenden und den Fehler in geeigneter Weise ausfindig machen.
Hinweise:
• Wird während der Dateneingabe ein Trigger-Fehler beim Bestätigen bzw. Löschen eines Datensatzes zurückgegeben, wird der Fehler wie ein einmaliger indizierter Fehler behandelt. Der Fehlerdialog wird angezeigt und Sie bleiben weiter in der Dateneingabe. Auch wenn Sie eine Datenbank nur in der Designumgebung einsetzen und nicht in der Anwendungsumgebung, können Sie die Vorteile von Triggern nutzen.
• Erzeugt ein Trigger einen Fehler, während gerade ein Befehl auf eine Datensatzauswahl ausgeführt wird, z.B. DELETE SELECTION, stoppt diese Operation sofort, d.h. die Auswahl ist u.U. nicht vollständig bearbeitet worden. Solch ein Fall erfordet vom Entwickler eine geeignete Abwicklung, wie z.B. die temporäre Erhaltung der Auswahl, Bearbeiten und Beheben des Fehlers vor Ausführen des Triggers, o. ä.
• Auch wenn ein Trigger keinen Fehler zurückgibt ($0:=0), heißt das nicht zwingend, dass die Datenbankoperation erfolgreich war – es kann ein Verstoß gegen den einmaligen Index eintreten. Handelt es sich bei der Operation um die Aktualisierung eines Datensatzes, kann dieser gesperrt sein, ein E/A Fehler kann auftreten, uvm.. Das Prüfen erfolgt nach Ausführung des Triggers. Auf höherer Ebene des ausführenden Prozesses dagegen sind die von der Datenbank-Engine oder einem Trigger zurückgegebenen Fehler dieselben – ein Trigger-Fehler ist ein Fehler der Datenbank-Engine.
Trigger und 4D Architektur
Trigger arbeiten auf der Ebene der Datenbank-Engine. Das zeigt folgendes Schema:
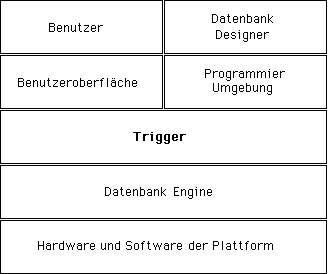
Trigger werden auf dem Rechner ausgeführt, auf dem die Datenbank-Engine liegt. Das ist im 4D Einzelplatzbetrieb offensichtlich. Im Mehrplatzbetrieb dagegen werden Trigger im ausführenden Prozess auf dem Server-Rechner ausgeführt (im Zwillingsprozess des Prozesses, der den Trigger ausgelöst hat), und nicht auf dem Client-Rechner .
Wird ein Trigger ausgelöst, läuft er im Kontext des Prozesses, der die Datenbankoperation versucht. Der Prozess, der die Trigger-Ausführung auslöst, heißt auslösender Prozess.
Die in diesem Kontext enthaltenen Elemente sind unterschiedlich, je nachdem ob die Datenbank mit 4D im lokalen Modus oder mit 4D Server ausgeführt wird:
• Mit 4D im lokalen Modus arbeiten Trigger mit aktuellen Auswahlen, aktuellen Datensätzen, Tabellen im Lese-/Schreibmodus und Operationen zum Sperren des Datensatzes des auslösenden Prozesses.
• Mit 4D Server wird nur der Kontext der Datenbank des auslösenden Client Prozesses beibehalten. (gesperrte Datensätze, Lese-/Schreibstatus, etc.) 4D Server garantiert auch, dass der aktuelle Datensatz der Trigger-Tabelle korrekt gesetzt wird. Die anderen Elemente dieses Kontexts, z.B. aktuelle Auswahlen, gehören zum Trigger Prozess.
Verwenden Sie andere Objekte der Datenbank oder der Programmiersprache der 4D Umgebung mit Bedacht, da ein Trigger auf einem anderen Rechner als dem, der den Prozess auslöst, ausgeführt werden kann. Das ist mit 4D Server der Fall!
• Interprozessvariablen: Ein Trigger hat Zugriff auf die Interprozessvariablen des Rechners, auf dem er ausgeführt wird. Mit 4D Server kann er auch auf einen anderen Rechner, als dem mit dem auslösenden Prozess zugreifen.
• Prozessvariablen: Jeder Trigger hat seine eigene Tabelle mit den Prozessvariablen. Ein Trigger hat keinen Zugriff auf die Prozessvariablen des auslösenden Prozesses.
• Lokale Variablen: Sie können in einem Trigger lokale Variablen verwenden. Sie gelten während der Ausführung des Triggers; sie werden für jede Ausführung erstellt und anschließend wieder gelöscht.
• Semaphoren: Ein Trigger kann globale Semaphoren testen und setzen, und zwar auf dem Rechner, wo er ausgeführt wird. Ein Trigger muss jedoch schnell ablaufen. Deshalb ist Vorsicht geboten, wenn Sie Semaphoren von Triggern aus testen oder setzen wollen.
• Mengen und temporäre Auswahlen: Verwenden oder setzen Sie eine Menge bzw. eine temporäre Auswahl von Triggern heraus, arbeiten Sie auf dem Rechner, von welchem die Trigger ausgeführt werden. Im Client/Server Modus sind auf dem Client-Rechner erstellte Prozessmengen und temporäre Auswahlen (den Namen ist weder $ noch <> vorangestellt) in einem Trigger sichtbar.
• Benutzeroberfläche: Verwenden Sie in einem Trigger KEINE Elemente der Benutzeroberfläche, wie z.B. Warnungen, Meldungen und Dialogboxen. Analog dazu sollten Sie auch den Schrittmodus für Trigger im Debugger ausgrenzen. Denn Trigger im Client/Server-Betrieb laufen auf dem Server-Rechner. Eine Meldung auf dem Server-Rechner hilft dem Benutzer auf dem Client-Rechner nicht. Deshalb sollte der aufrufende Prozess die Benutzeroberfläche verwalten.
Trigger und Transaktionen
Sie müssen Transaktionen auf der Ebene des auslösenden Prozesses verwalten und nicht auf der Trigger-Ebene. Wollen Sie während Ausführung eines Triggers mehrere Datensätze hinzufügen, ändern oder löschen, müssen Sie zuerst mit der Funktion In transaction innerhalb des Triggers prüfen, ob der auslösende Prozess derzeit in Transaktion ist. Ist das nicht der Fall, findet der Trigger höchstwarscheinlich einen gesperrten Datensatz vor. Es macht also keinen Sinn, eine Operation auf Datensätze zu starten, wenn der auslösende Prozess nicht in Transaktion ist. Geben Sie in $0 einen Fehler zurück, der dem auslösenden Prozess signalisiert, dass die angestrebte Datenbankoperation in Transaktion ausgeführt werden muss. Sonst kann der auslösende Prozess, wenn er auf gesperrte Datensätze stößt, die Aktionen des Triggers nicht zurückfahren.
Hinweis: 4D ruft nach der Ausführung von VALIDATE TRANSACTION keine Trigger auf. Das optimiert das Zusammenspiel von Triggern und Transaktionen, denn so werden Trigger nicht zweimal aufgerufen.
Trigger verschachteln
Wir gehen von folgender Beispielstruktur aus:
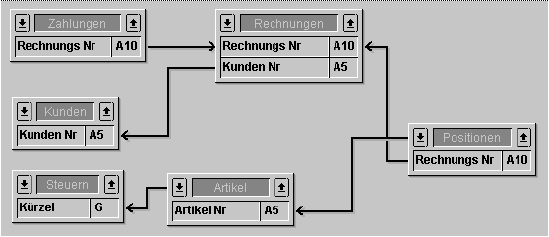
Hinweis: Die Tabellen sind verkürzt; sie haben natürlich mehr Felder als hier gezeigt.
Wir nehmen an, dass die Datenbank das Löschen einer Rechnung zulässt. So können wir nachvollziehen, wie solch eine Operation auf Trigger-Ebene verwaltet wird (Löschen ist auf Prozessebene möglich).
Zur Wahrung der relationalen Integrität der Daten müssen beim Löschen einer Rechnung im Trigger für [Rechnungen] folgende Aktionen ablaufen:
• Im Datensatz [Kunden] den Wert im Feld Gesamtumsatz um den Rechungsbetrag kürzen.
• Alle mit der Rechnung verknüpften Datensätze [Positionen] löschen.
• Daraus ergibt sich, dass der Trigger zu [Positionen] den Wert im Feld Anzahl verkauft des Datensatzes [Artikel] verringert, der zum zu löschenden Artikel gehört.
• Alle mit der gelöschten Rechnung verknüpften Datensätze [Zahlungen] löschen.
1. Der Trigger für [Rechnungen] muss diese Aktionen nur ausführen, wenn der auslösende Prozess in Transaktion ist, so dass bei gesperrten Datensätzen ein Zurücksetzen möglich ist.
2. Der Trigger für [Positionen] ist mit dem Trigger für [Rechnungen] verschachtelt. Der Trigger [Positionen] wird innerhalb des Triggers [Rechnungen] ausgeführt. Denn durch Aufrufen von DELETE SELECTION im Trigger [Rechnungen] erfolgt das Löschen der Positionen.
Wir gehen davon aus, dass für alle Tabellen dieses Beispiels Trigger für alle Datenbankereignisse aktiviert sind. Die Trigger sind dann folgendermaßen verschachtelt:
• Trigger [Rechnungen] wird ausgelöst, da der auslösende Prozess eine Rechnung löscht • Trigger [Kunden] wird ausgelöst, da der Trigger [Rechnungen] das Feld Gesamtumsatz aktualisiert • Trigger [Positionen] wird ausgelöst, da der Trigger [Rechnungen] einen Artikel löscht (wiederholt) • Trigger [Artikel] wird ausgelöst, da der Trigger [Positionen] das Feld Anzahl verkauft aktualisiert • Trigger [Zahlungen] wird ausgelöst, da der Trigger [Rechnungen] eine Zahlung löscht (wiederholt)
In dieser Verschachtelung läuft der Trigger [Rechnungen] auf Ebene 1 ab, die Trigger [Kunden], [Positionen] und [Zahlungen] auf Ebene 2 und der Trigger [Artikel] auf Ebene 3.
Innerhalb der Trigger können Sie mit der Funktion Trigger level prüfen, auf welcher Ebene der Trigger abläuft. Mit dem Befehl TRIGGER PROPERTIES erhalten Sie Informationen über die anderen Ebenen.
Wird zum Beispiel ein Datensatz [Artikel] auf Prozessebene gelöscht, wird der Trigger [Artikel] auf Ebene 1, nicht auf Ebene 3 ausgeführt.
Mit Trigger level und TRIGGER PROPERTIES können Sie den Grund für eine Aktion prüfen. In unserem Beispiel wird eine Rechnung auf Prozessebene gelöscht. Löschen wir einen Datensatz [Kunden] auf Prozessebene, sollte der Trigger [Kunden] versuchen, alle mit diesem Kunden verknüpften Rechnungen zu löschen. Das heißt, dass der Trigger [Rechnungen] – wie oben beschrieben – ausgelöst wird, jedoch aus einem anderen Grund. Innerhalb des Triggers [Rechnungen] können Sie prüfen, ob er auf Ebene 1 oder 2 abgelaufen ist. Lief er auf Ebene 2 ab, können Sie prüfen, ob er aktiv wurde, weil der Datensatz [Kunden] gelöscht wurde. In diesem Fall erübrigt sich die Aktualisierung des Feldes Gesamtumsatz.
Sequenznummer in einem Trigger
Beim Verwalten eines Datenbankereignisses On saving new record können Sie die Funktion Sequence number aufrufen, um für die Datensätze einer Tabelle eine einmalige Kennummer zu unterhalten.
Beispiel
` Trigger für Tabelle [Rechnungen] Case of : (Database event=On Saving new record) ` ... [Rechnungen]Kennummer:=Sequence number ([Rechnungen]) ` ... End case
Referenz
Database event, Methoden, Record number, Trigger level, TRIGGER PROPERTIES.
|
|
|
|
|
|
|
|
|
|
|