






|
|
|
|
|
|
|
|
|
|
version 11.3 (Modifiée)
Fondamentalement, le moteur SQL de 4D est conforme à la norme SQL92. Cela signifie que, pour une description détaillée des commandes, fonctions, opérateurs et syntaxes à utiliser, vous pouvez vous référer à n'importe quelle documentation sur le SQL92. De multiples ressources sur ce thème sont disponibles, par exemple, sur Internet.
Cependant, le moteur SQL de 4D ne prend pas en charge 100 % des fonctions du SQL92 et propose en outre des fonctions supplémentaires, non présentes dans cette norme.
Ce paragraphe décrit les principales implémentations et limitations du moteur SQL de 4D.
Limitations générales
Le moteur SQL de 4D étant intégré au coeur de la base de données de 4D, les limitations relatives au nombre maximum de tables, de colonnes (champs) et d'enregistrements par base ainsi que les règles de nommage des tables et des colonnes sont identiques à celles du moteur standard de 4D. Elles sont listées ci-dessous :
• Nombre maximum de tables par base : deux milliards en théorie, mais limitation à 32767 pour des raisons de compatibilité avec 4D v11.
• Nombre maximum de colonnes (champs) par table : deux milliards en théorie, mais limitation à 32767 pour des raisons de compatibilité avec 4D v11.
Note : Dans 4D v11 SQL "Standard edition", les nombres maximum de tables et de colonnes par table sont limités respectivement à 255 et 511.
• Nombre maximum de lignes (enregistrements) par table : un milliard.
• Nombre maximum de clés d'index : un milliard x 64.
• Une clé primaire ne peut pas être une valeur NULL et doit être unique. Il n'est pas obligatoire d'indexer les colonnes (champs) clés primaires.
• Nombre maximum de caractères pour les noms de tables et de champs : 31 caractères (limitation de 4D).
Il n'est pas possible de créer plusieurs tables avec le même nom. Les mécanismes de contrôle standard de 4D sont appliqués.
Types de données
Le tableau suivant indique les types de données pris en charge dans le SQL de 4D ainsi que leur type correspondant dans 4D :
| Type 4D SQL | Description | Type 4D v11 |
| Varchar | Texte aphanumérique | Texte |
| Real | Nombre à virgule flottante compris dans | Réel |
| l'intervalle +/-3,4E38 | ||
| Numeric | Nombre compris dans l'intervalle +/-2E64 | Entier 64 bits |
| Float | Nombre à virgule flottante (virtuellement infini) | Réel |
| Smallint | Nombre compris entre -32 768 et 32 767 | Entier |
| Int | Nombre compris entre -2 147 483 648 et 2 147 483 647 | Entier long |
| Bit | Champ qui n'accepte que la valeur TRUE ou FALSE | Booléen |
| Boolean | Champ qui n'accepte que la valeur TRUE ou FALSE | Booléen |
| Blob | Jusqu'à 2 Go ; tout objet binaire tel qu'une image, un | BLOB |
| document, une application... | ||
| Bit varying | Jusqu'à 2 Go ; tout objet binaire tel qu'une image, un | BLOB |
| document, une application... | ||
| Clob | Jusqu'à 2 Go de texte. Ce type de colonne (champ) | Texte |
| ne peut pas être indexé. Il n'est pas stocké dans | ||
| l'enregistrement lui-même. | ||
| Text | Jusqu'à 2 Go de texte. Ce type de colonne (champ) | Texte |
| ne peut pas être indexé. Il n'est pas stocké dans | ||
| l'enregistrement lui-même. | ||
| Timestamp | Date et Heure sous la forme Jour Mois Année | Parties Date et Heure |
| Heures:Minutes:Secondes:Millisecondes | gérées séparément | |
| (conversion auto) | ||
| Duration | Durée sous la forme Jour:Heure:Minutes:Secondes: | Heure |
| Millisecondes | ||
| Interval | Durée sous la forme Jour:Heure:Minutes:Secondes: | Heure |
| Millisecondes | ||
| Image | Image PICT jusqu'à 2 Go | Image |
La conversion entre les types de données numériques est automatique. Les chaînes qui représentent un nombre ne sont pas converties en valeur numérique. L'opérateur de transtypage CAST permet de convertir des valeurs d'un type en un autre.
Les types de données SQL suivants ne sont pas implémentés :
• NCHAR
• NCHAR VARYING
Valeurs NULL dans 4D
La valeur NULL est implémentée dans le langage SQL de 4D ainsi que dans le moteur de base de données de 4D. En revanche, cette valeur n'existe pas dans le langage de 4D. Il est toutefois possible de lire et d'écrire la valeur NULL dans un champ 4D via les commandes Valeur champ Null et FIXER VALEUR CHAMP NULL.
Compatibilité des traitements et option Traduire les NULL en valeurs vides
Pour des raisons de compatibilité dans 4D v11, les valeurs NULL stockées dans les tables des bases de données 4D sont automatiquement converties en valeurs par défaut lors des manipulations effectuées via le langage de 4D. Par exemple, dans le cas de l'instruction suivante :
mavarAlpha:=[matable]MonChpAlpha
... si le champ MonchpAlpha contient la valeur NULL, la variable mavarAlpha contiendra "" (chaîne vide).
Les valeurs par défaut dépendent du type de données :
• Pour les types Alpha et Texte : ""
• Pour les types Numérique (réel), Entier et Entier long : 0
• Pour le type Date : "00/00/00"
• Pour le type Heure : "00:00:00"
• Pour le type Booléen : Faux
• Pour le type Image : Image vide
• Pour le type BLOB : BLOB vide
En revanche, ce mécanisme ne s'applique pas en principe aux traitements effectués au niveau du moteur de la base de données 4D, tels que les recherches. En effet, la recherche d'une valeur "vide" (par exemple mavaleur=0) ne trouvera pas les enregistrements stockant la valeur NULL, et inversement. Lorsque les deux types de valeurs (valeurs par défaut et NULL) cohabitent dans les enregistrements pour un même champ, certains traitements peuvent être faussés ou nécessiter du code supplémentaire.
Pour éviter ces désagréments, une option permet d'uniformiser tous les traitements dans le langage de 4D v11 : Traduire les NULL en valeurs vides. Cette option, accessible dans l'Inspecteur des champs de l'éditeur de structure, permet d'étendre le principe d'usage des valeurs par défaut à tous les traitements. Les champs contenant la valeur NULL seront systématiquement considérés comme contenant la valeur par défaut. Cette option est cochée par défaut.
La propriété Traduire les NULL en valeurs vides est prise en compte à un niveau très bas du moteur de la base de données. Elle agit notamment sur la routine Valeur champ Null.
Refuser l'écriture de la valeur NULL
La propriété de champ Refuser l'écriture de la valeur NULL permet d'interdire le stockage de la valeur NULL :
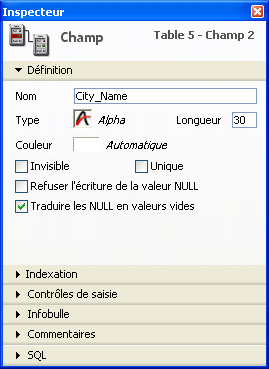
Lorsque cet attribut est coché pour un champ, il ne sera pas possible de stocker la valeur NULL dans ce champ. Cette propriété de bas niveau correspond précisément à l'attribut NOT NULL du SQL.
De manière générale, si vous souhaitez pouvoir utiliser des valeurs NULL dans votre base de données 4D, il est conseillé d'utiliser exclusivement le langage SQL de 4D.
Note: Dans 4D, les champs peuvent également avoir l'attribut "Obligatoire". Les deux notions sont proches mais leur portée est différente : l'attribut "Obligatoire" est un contrôle de saisie, tandis que l'attribut "Refuser l'écriture de la valeur NULL" agit au niveau du moteur de la base de données.
Si un champ disposant de cet attribut reçoit la valeur NULL, une erreur est générée.
Option "Disponible via SQL"
La propriété "Disponible via SQL", disponible pour les méthodes projet, permet de contrôler l'exécution des méthodes projet de 4D via le SQL.
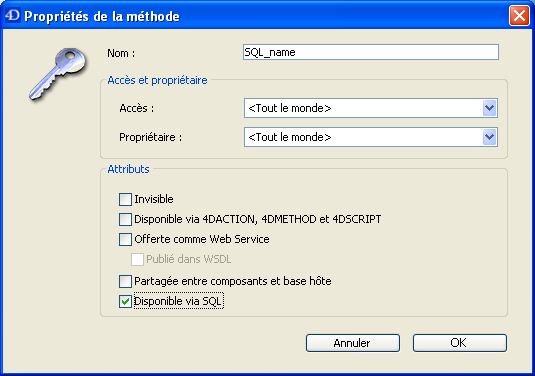
Lorsqu'elle est cochée, cette option autorise l'exécution de la méthode projet par le moteur SQL de 4D. Elle est désélectionnée par défaut, ce qui signifie que, sauf autorisation explicite, les méthodes projet de 4D sont protégées et peuvent pas être appelées par le moteur SQL de 4D.
Cette propriété s'applique à toutes les requêtes SQL internes et externes — exécutées via le driver ODBC, le code SQL inséré dans les balises Debut SQL/Fin SQL ou la commande CHERCHER PAR SQL.
Notes :
• Même si une méthode dispose de l'attribut "Disponible via SQL", les accès définis au niveau des Préférences et des propriétés de la méthode sont pris en compte pour l'exécution de la méthode.
• La fonction ODBC SQLProcedure retourne uniquement les méthodes projet disposant de l'attribut "Disponible via SQL".
Options moteur SQL
Deux options situées dans la page SQL/Configuration des Préférences permettent de modifier le fonctionnement du moteur SQL de 4D.

• Transactions Auto-commit : cette option permet d'activer le mécanisme d'auto-commit dans le moteur SQL. Le mode auto-commit a pour but de préserver l'intégrité référentielle des données. Lorsque cette option est cochée, toute requête SELECT, INSERT, UPDATE et DELETE (SIUD) effectuée en-dehors d'une transaction est automatiquement incluse dans une transaction ad hoc. Ce principe garantit que les requêtes seront entièrement exécutées ou, en cas d'erreur, intégralement annulées.
Les requêtes incluses dans une transaction (gestion personnalisée de l'intégrité référentielle) ne sont pas affectées par cette option.
Lorsque cette option n'est pas cochée, aucune transaction automatique n'est générée (à l'exception des requêtes SELECT... FOR UPDATE, reportez-vous à la description de la commande SELECT). Par défaut, cette option n'est pas cochée.
Vous pouvez également gérer cette option par programmation à l'aide de la commande FIXER PARAMETRE BASE.
Note : Seules les bases locales interrogées par le moteur SQL de 4D sont affectées par ce paramètre. Dans le cas de bases externes, le mécanisme d'auto-commit est pris en charge par les moteurs SQL distants.
• Tenir compte de la casse des caractères pour les comparaisons de chaînes : cette option permet de modifier le mode de prise en compte de la casse des caractères dans les requêtes SQL. Elle est cochée par défaut, ce qui signifie que le moteur SQL établit une différence entre les majuscules et les minuscules lors des comparaisons de chaînes (tris et recherches). Par exemple "ABC"="ABC" mais "ABC" # "Abc".
Dans certains cas, par exemple pour aligner le fonctionnement du moteur SQL sur celui du moteur 4D, vous pourrez souhaiter que les comparaisons de chaînes ne tiennent pas compte de la casse ("ABC"="Abc"). Pour cela, il suffit de désélectionner l'option.
Vous pouvez également gérer cette option par programmation à l'aide de la commande FIXER PARAMETRE BASE.
Schémas
4D v11 SQL implémente le concept de schémas. Un schéma est un objet virtuel contenant des tables de la base. Dans le SQL, le concept de schémas a pour but de permettre l'attribution de droits d'accès spécifiques à des ensembles d'objets de la base de données. Les schémas découpent la base en entités indépendantes dont l'assemblage représente la base entière. Autrement dit, une table appartient toujours à un et un seul schéma.
• Pour créer un schéma, vous devez utiliser la commande CREATE SCHEMA. Vous utilisez ensuite les commandes GRANT et REVOKE pour configurer les types d'accès des schémas.
• Pour associer une table à un schéma, vous pouvez appeler les commandes CREATE TABLE ou ALTER TABLE. Vous pouvez également utiliser le pop up menu "Schémas" de l'Inspecteur de l'éditeur de Structure de 4D, qui liste tous les schémas définis dans la base :
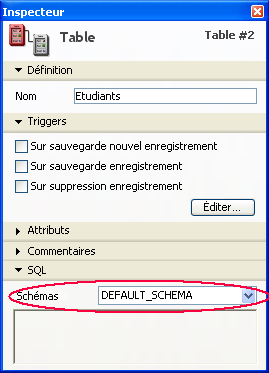
• La commande DROP SCHEMA permet de supprimer un schéma.
Note : Le contrôle des accès via les schémas s'applique uniquement aux connexions depuis l'extérieur. Le code SQL exécuté à l'intérieur de 4D via les balises Debut SQL/Fin SQL, SQL EXECUTER, CHERCHER PAR SQL... dispose toujours d'un accès complet.
Tables système
Le catalogue SQL de 4D comporte sept tables système, accessible à tout utilisateur SQL disposant des droits d'accès en lecture : _USER_TABLES, _USER_COLUMNS, _USER_INDEXES, _USER_CONSTRAINTS, _USER_IND_ COLUMNS, _USER _CONS_ COLUMNS et _USER_SCHEMAS.
Conformément aux usages dans le monde SQL, les tables système décrivent la structure de la base de données. Voici le descriptif de ces tables et de leurs champs :
| _USER_TABLES | Décrit les tables utilisateurs de la base | |
| TABLE_NAME | VARCHAR | Nom de table |
| TEMPORARY | BOOLEAN | Vrai si la table est temporaire, faux sinon |
| TABLE_ID | INT64 | Numéro de table |
| SCHEMA_ID | INT32 | Numéro de schéma |
| _USER_COLUMNS | Décrit les colonnes des tables utilisateurs de la base | |
| TABLE_NAME | VARCHAR | Nom de table |
| COLUMN_NAME | VARCHAR | Nom de colonne |
| DATA_TYPE | INT32 | Type de colonne |
| DATA_LENGTH | INT32 | Longueur de colonne |
| NULLABLE | BOOLEAN | Vrai si la colonne accepte des valeurs NULL, faux sinon |
| TABLE_ID | INT64 | Numéro de table |
| COLUMN_ID | INT64 | Numéro de colonne |
| _USER_INDEXES | Décrit les index utilisateurs de la base | |
| INDEX_ID | VARCHAR | Numéro d'index |
| INDEX_NAME | VARCHAR | Nom d'index |
| INDEX_TYPE | INT32 | Type d'index |
| TABLE_NAME | VARCHAR | Nom de table avec index |
| UNIQUENESS | BOOLEAN | Vrai si l'index impose une contrainte d'unicité, faux sinon |
| TABLE_ID | INT64 | Numéro de table avec index |
| _USER_IND_COLUMNS | Décrit les colonnes des index utilisateurs de la base | |
| INDEX_ID | VARCHAR | Numéro d'index |
| INDEX_NAME | VARCHAR | Nom d'index |
| TABLE_NAME | VARCHAR | Nom de table avec index |
| COLUMN_NAME | VARCHAR | Nom de colonne avec index |
| COLUMN_POSITION | INT32 | Position de colonne dans l'index |
| TABLE_ID | INT64 | Numéro de table avec index |
| COLUMN_ID | INT64 | Numéro de colonne |
| _USER_CONSTRAINTS | Décrit les contraintes utilisateurs de la base | |
| CONSTRAINT_ID | VARCHAR | Numéro de contrainte |
| CONSTRAINT_NAME | VARCHAR | Nom de contrainte |
| CONSTRAINT_TYPE | VARCHAR | Type de contrainte |
| TABLE_NAME | VARCHAR | Nom de table avec contrainte |
| TABLE_ID | INT64 | Numéro de table avec contrainte |
| DELETE_RULE | VARCHAR | Règle de suppression – CASCADE ou RESTRICT |
| RELATED_TABLE_NAME | VARCHAR | Nom de table liée |
| RELATED_TABLE_ID | INT64 | Numéro de table liée |
| _USER_CONS_COLUMNS | Décrit les colonnes des contraintes utilisateurs de la base | |
| CONSTRAINT_ID | VARCHAR | Numéro de contrainte |
| CONSTRAINT_NAME | VARCHAR | Nom de contrainte |
| TABLE_NAME | VARCHAR | Nom de table avec contrainte |
| TABLE_ID | INT64 | Numéro de table avec contrainte |
| COLUMN_NAME | VARCHAR | Nom de colonne avec contrainte |
| COLUMN_ID | INT64 | Numéro de colonne avec contrainte |
| COLUMN_POSITION | INT32 | Position de colonne dans une contrainte |
| RELATED_COLUMN_NAME | VARCHAR | Nom de colonne liée dans une contrainte |
| RELATED_COLUMN_ID | INT32 | Numéro de colonne liée dans une contrainte |
| _USER_SCHEMAS | Décrit les schémas de la base | |
| SCHEMA_ID | INT32 | Numéro de schéma |
| SCHEMA_NAME | VARCHAR | Nom de schéma |
| READ_GROUP_ID | INT32 | Numéro du groupe ayant accès en lecture |
| READ_GROUP_NAME | VARCHAR | Nom du groupe ayant accès en lecture |
| READ_WRITE_GROUP_ID | INT32 | Numéro du groupe ayant accès en lecture-écriture |
| READ_WRITE_GROUP_NAME | VARCHAR | Nom du groupe ayant accès en lecture-écriture |
| ALL_GROUP_ID | INT32 | Numéro du groupe ayant un accès complet |
| ALL_GROUP_NAME | VARCHAR | Nom du groupe ayant un accès complet |
Note : Les tables système sont affectées à un schéma particulier nommé SYSTEM_SCHEMA. Ce schéma ne peut être ni modifié ni supprimé. Il n'apparaît pas dans la liste des schémas affichée dans l'Inspecteur de tables. Il est accessible en mode Lecture seulement à tout utilisateur.
Connexions aux sources SQL
L'architecture multi-bases est implémentée au niveau du serveur SQL de 4D. Depuis 4D, il est possible :
• de se connecter à une base existante à l'aide de la commande SQL LOGIN.
• de passer d'une base à l'autre en utilisant les commandes 4D SQL LOGIN et SQL LOGOUT.
|
|
|
|
|
|
|
|
|
|