



Introduction▲
Voici la première de deux notes sur l'utilisation des clusters (ensembles enregistrés) pour améliorer radicalement les performances d'une base. La première partie couvrira la création et la sauvegarde des clusters. La deuxième traitera de l'utilisation effective des clusters pour accéder aux données.
Littéralement, Cluster signifie grappe ou agglomérat.
Utilisation des ensembles▲
Les ensembles ! Tous les développeurs 4D en ont entendu parler. Presque chaque développeur fait un UTILISER ENSEMBLE (« UserSet ») ou quelque chose d'équivalent, comme LIRE ENREGISTREMENTS MARQUES, pour passer en sélection courante les enregistrements marqués par l'utilisateur.
Malheureusement, pour beaucoup d'utilisateurs, l'usage des ensembles s'arrête là. Je l'ai souvent déclaré, si votre base est lente, vous devriez essayer d'utiliser les ensembles pour améliorer ses performances.
Par exemple
Considérons un état avec la présentation suivante, dans lequel vous voulez le pourcentage du total des ventes (hors taxes, frais d'envois, etc.) entre deux dates.
Note : les champs nécessaires sont éparpillés dans toute la base, chacun dans une table différente : [Client]Etat, [Facture]DateFacture, [LigneFacture]Montant, [Produit]Genre.

Pour calculer le pourcentage dans chaque cellule, vous avez besoin non seulement du total général du tableau, mais aussi d'une sélection de lignes de factures dans l'intervalle de dates par état du client et par genre du produit pour calculer la somme dans une cellule particulière. Cela représente beaucoup de requêtes. Tenant compte du fait que la table des clients se situe deux liens plus loin, cela augmente encore la durée de recherche. Il y a quelques années, j'ai vu du code écrit pour traiter cet état où les requêtes effectuées pour chaque cellule prenaient plus de 20 minutes à s'exécuter.
D'un autre côté, réécrivons le concept de cet état.
Note : Ce concept ne contient pas nécessairement tout le code nécessaire pour éditer l'état, juste ce qui est nécessaire pour accéder rapidement aux enregistrements dont on a besoin pour chaque cellule de l'état.
CHERCHER([LigneFacture];[Facture]Date_Facture>=dDebut;*)
CHERCHER([LigneFacture]; & [Facture]Date_Facture<=dFin)
Jusqu'ici, nous n'avons pas gagné de temps et ceci devait être fait avant l'impression de l'état, quelle que soit la méthode utilisée. Mais, au lieu de rechercher les données pour chacune des cellules, procédons comme suit :
NOMMER ENSEMBLE([LigneFacture];"Intervalle")
TOUT SELECTIONNER([Produit])
VALEURS DISTINCTES([Produit]Genre;atGenre)
`On va rechercher une fois par genre, ce qui sera assez rapide,
`le champ étant indexé et situé à seulement un lien plus loin.
`Note : ceci suppose un lien automatique
Boucle ($i;1;Taille tableau(atGenre))
CHERCHER([LigneFacture];[Produit]Genre=atGenre{$i})
`Créer un ensemble pour chaque genre
NOMMER ENSEMBLE([LigneFacture];atGenre{$i})
Fin de boucle
TOUT SELECTIONNER([Client])
VALEURS DISTINCTES([Client]Etat;atEtat)
Boucle ($j;1;Taille tableau(atEtat))
`faire une seule recherche par état
CHERCHER([LigneFacture];[Client]Etat=atEtat{$i})
`Créer un ensemble pour chaque état,
`inutile de le réduire à ce stade
NOMMER ENSEMBLE([LigneFacture];"Etat")
Boucle ($i;1;Taille tableau(atGenre))
`Constituer l'ensemble des [LigneFacture] qui correspondent à l'état et au genre
INTERSECTION("Etat";atGenre{$i};"EtatGenre")
`Restreindre à l'intervalle de dates
INTERSECTION("EtatGenre";"Intervalle";"EtatGenre")
`C'est cette sélection qui permet le calcul dans une cellule.
Fin de boucle
Fin de boucle
Ce modèle de code réduit les recherches qui étaient toutes multicritères (nombre de critères = nombre de lignes par nombre de colonnes) à des recherches monocritères (plus rapides que les multicritères) dont le nombre est le nombre de lignes plus le nombre de colonnes.
Il n'est pas nécessaire d'être un génie des mathématiques pour comprendre que les ensembles peuvent diminuer radicalement le temps de recherche pour simplement trouver des enregistrements pour un état. En fait, avec les mêmes enregistrements, la même machine et la même base, ce qui prenait 20 minutes comme je le mentionnais ci-dessus a été réduit à moins de 2 minutes une fois réécrit en utilisant les ensembles. Une économie de temps de plus de 90 %.
Les ensembles sont très commodes à utiliser et peuvent réduire drastiquement les temps d'accès aux données. Même le chargement d'un ensemble stocké sur disque est bien plus rapide qu'un nouvel accès aux données.
Mais, le problème avec les ensembles, c'est que les données changent constamment. Et, une fois un ensemble créé, si les données sont modifiées, l'ensemble n'est plus pertinent. Pour l'état ci-dessus, il est bien peu probable que les données soient modifiées pendant que l'état s'exécute. Mais, il serait bien agréable de disposer d'ensembles qui puissent se tenir à jour lorsque les données sont modifiées. La solution de ce problème est le sujet de la présente note technique : les clusters. Chaque fois qu'un enregistrement est enregistré, les clusters correspondants sont mis à jour avec l'information 'ensembliste' modifiée.
L'usage des clusters pourrait-il améliorer encore la performance de cet état ? C'est possible, mais selon la fréquence d'utilisation de cet état, le temps d'implémentation des clusters pourrait ne pas être justifié pour un usage hebdomadaire. En revanche, utilisez les clusters pour des tâches plus fréquentes. La base exemple jointe à cette note technique implémente des clusters pour effectuer une tâche bien plus complexe, la recherche dans du texte.
Aperçu sur les clusters▲
En 2000, nous avons implémenté notre base d'information technique online KnowledgeBase (site 4D US).
En 2001, nous étions reconnus dans l'industrie comme ayant un des meilleurs sites d'information technique sur Internet. Ce qui a impressionné les commentateurs, c'est la rapidité des requêtes dans la base. J'ai été contacté par plusieurs personnes qui voulaient connaître exactement la configuration serveur et logiciel que j'utilisais pour obtenir une rapidité aussi impressionnante. Ils supposaient que c'était une grappe de serveurs avec un « back-end » Oracle ou SQL. Pas un seul ne m'a cru lorsque je leur ai dit que ce n'était rien d'extraordinaire, juste une machine monoprocesseur banale, et, bien sûr, une base de données 4D, notre propre développement. Alors, qu'est-ce qui faisait que c'était si rapide ? Les clusters. (Au fait, c'est toujours aussi rapide aujourd'hui, et ça utilise toujours la même machine qu'en 2000).
Cela fait plus de dix ans que la communauté 4D parle des clusters, depuis qu'ils ont été introduits comme une technique efficace pour sauver et utiliser des ensembles. Dans le temps, ils étaient sauvés dans des variables textes. Quel effort c'était. Comme les variables textes sont limitées à 32 000 caractères, dès qu'une de vos tables comportait plus de 256 000 enregistrements, il fallait un effort supplémentaire pour concaténer les variables textes afin d'obtenir des ensembles convenables. Le problème a été simplifié avec l'introduction des BLOBs en version 6. On sauve l'ensemble dans un document et on fait DOCUMENT VERS BLOB pour sauver l'ensemble dans les données. On inverse le processus pour restaurer l'ensemble. Stephen Willis a écrit une série d'articles pour le magazine Dimensions en 1999 afin de documenter cette technique.
Ainsi, cette note technique ne propose pas une idée nouvelle à la communauté 4D. Mais, elle propose une technique nouvelle pour transférer les « ensembles » des données vers des ensembles 4D sans écrire STOCKER ENSEMBLE et CHARGER ENSEMBLE comme dans les précédents articles sur les clusters. Elle montrera aussi comment faire de la concordance de textes avec les clusters, une question qui n'a pas été abordée auparavant. Si vous utilisez déjà les clusters dans votre base et qu'ils font exactement ce que vous voulez, félicitations, vous pouvez sauter cette note technique et peut-être faire un meilleur usage de votre temps. Cependant, si vous n'avez jamais utilisé un cluster, c'est peut-être le bon moment pour y penser.
La structure interne d'un ensemble et d'un cluster▲
Un ensemble est simplement un tableau de bits qui représente la présence ou l'absence d'un enregistrement dans l'ensemble. Chaque enregistrement est décrit par un bit dans l'ensemble. De ce fait, les ensembles sont très économiques en mémoire : un bit par enregistrement de la table. L'utilisation d'un ensemble passe en sélection courante les enregistrements de l'ensemble. Ils sont donc extrêmement rapides comparés à toute autre méthode de recherche.

Dans cet exemple d'ensemble, les enregistrements 3, 4, 8, 10 13, 15 et 17 sont dans l'ensemble. Les autres n'y sont pas.
Quoique différents en interne, les ensembles sont très semblables à des tableaux booléens.
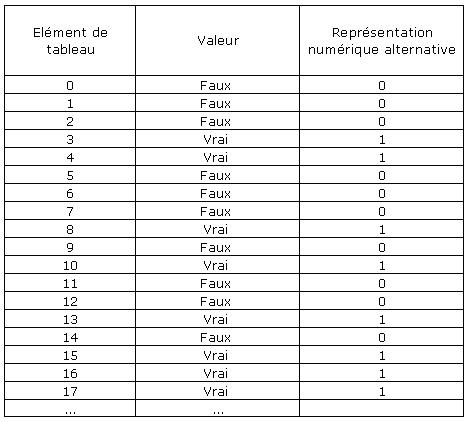
Si vous regardez la colonne de représentation numérique, vous constatez qu'elle correspond exactement à l'exemple d'ensemble ci-dessus. Par chance, il existe dans 4D deux commandes qui permettent de passer d'un ensemble à un tableau booléen ou l'inverse. TABLEAU BOOLEEN SUR ENSEMBLE (tabBooléen{; ensemble}) et CREER ENSEMBLE SUR TABLEAU (table; tabEnrg{; nomEns}). Cette dernière commande est celle sur laquelle reposent les clusters dans la base exemple. Si nécessaire, nous créerons des ensembles à partir des tableaux stockés dans des BLOBs, dans le fichier de données. Dans cet exemple, le code manipule les tableaux de booléens pour adjoindre ou retirer des enregistrements à l'ensemble, sans même avoir à créer les ensembles 4D avant d'en avoir effectivement besoin pour afficher des enregistrements. Ceci réduit le code et le temps nécessaires pour maintenir les clusters par rapport aux techniques précédemment décrites, car l'ensemble n'est plus écrit ou lu sur le disque et tout se fait en mémoire.
Cette simplification a un coût. Les tableaux booléens stockés dans un BLOB sont physiquement plus volumineux qu'un simple ensemble 4D. De ce fait, le fichier de données de la base est considérablement plus lourd. Néanmoins, avec la taille, la rapidité et le prix des disques durs aujourd'hui, ce n'est plus un problème.
Description de la base exemple▲
La base exemple a une table principale [BlocsTextes] avec deux champs principaux, Titre et ZoneTexte. Le résultat souhaité est de pouvoir chercher des enregistrements par mots ou même par extraits de texte présents n'importe où dans le titre ou les champs textes.
Pour cela, nous devons connaître chaque mot qui apparaît n'importe où dans ces deux champs. Chaque fois qu'un enregistrement est créé, tous les mots des deux champs sont analysés dans un tableau. Pour éliminer les mots non significatifs, une liste de mots communs appelés exceptions est définie. Si un mot du titre ou de la zone texte figure dans la liste des exceptions, il est ignoré. Parmi les exemples de la liste des exceptions : ou, et, le, il, elle, ce, etc. Cela se produit dans la méthode CLUSTER_Text2Array. Cette méthode traite virtuellement tout comme un délimiteur, sauf le signe moins, le point décimal et dans certains cas, l'underscore. Pour donner un exemple, le code est conçu pour laisser « Prod_ » intact avec n'importe quelle suite.
Ex : Prod_4Dwrite sera laissé intact et ne sera pas traité comme s'il s'agissait des deux mots Prod et 4Dwrite. Ceci n'est qu'un exemple d'implémentation d'un mot avec un contexte particulier.
Note : c'est effectivement le mot stocké dans Partner Central lorsque vous cherchez des informations sur le produit 4D Write. L'interface HTML gère la conversion du pop-up en Prod_4Dwrite pour la recherche.
Si (Faux)
` Méthode : CLUSTER_Text2Array(text;ptr)
` Created by: Kent Wilbur
` Objet: Analyse le texte dans des tableaux en laissant de côté les mots de
` la liste des exceptions
`Pour l'essentiel, nous ne voulons garder que les caractères, et tout caractère
`non alpha devrait être traité comme un séparateur et désigner la fin de mot.
`L'exception concerne les nombres. Les signes moins et les points (ou virgules)
`décimaux sont différents des tirets et points (ou virgules).
`De ce fait, lorsque un moins ou un décimal est rencontré, nous devons regarder
`les caractères environnants pour déterminer s'il s'agit
`d'un nombre qui inclut le caractère ou d'un tiret ou point (ou virgule) qui ne
`doit pas être inclus.
`Cette méthode traite les mots avec trait d'union comme deux mots séparés, elle
`pourrait être modifiée pour les traiter comme un seul mot.
`$1 = pointeur sur la zone texte à analyser
`$2 = pointeur sur la table de stockage des résultats
<>f_Version2003x1:=Vrai
<>fK_Wilbur:=Vrai
Fin de si
` Déclaration des paramètres
C_TEXTE($1;$tTextToParse)
C_POINTEUR($2;$pArray)
` Déclaration des variables locales
C_BOOLEEN($fDelimiter)
C_ENTIER LONG($i)
C_ENTIER LONG($LAscii)
C_ENTIER LONG($LMaximumLength)
C_ENTIER LONG($LSizeOfArray)
C_ENTIER LONG($LTextLength)
C_ENTIER LONG($LSizeOfArray;$Find;$LTextLength;$LPosition)
C_ALPHA(255;$sWord)
C_TEXTE($tTextToParse)
C_TEXTE($tWord)
` Réaffectation pour plus de lisibilité et d'efficacité
$tTextToParse:=$1
$pArray:=$2
` Déclaration des valeurs par défaut
$LMaximumLength:=25 `Cette valeur peut être modifiée si vous voulez autoriser la sauvegarde
`de mots plus longs. Néanmoins, 25 caractères devraient suffire à assurer l'unicité
`Note: If you change this value, you need to change the structure size also
`Note : Si vous changez cette valeur, vous devez aussi changer la taille de la structure.
TABLEAU TEXTE($pArray->;0)
$pArray->{0}:=""
$LSizeOfArray:=0
$sWord:=""
$LTextLength:=Longueur($tTextToParse)
Boucle ($i;1;$LTextLength)
$LAscii:=Code ascii($tTextToParse?$i?)
Si ($LAscii<48) | ($i=$LTextLength) | (($LAscii>=58) & ($LAscii<=64)) | (($LAscii>=91) &
($LAscii<=95)) | (($LAscii>=123) & ($LAscii<=127)) `break or last character
$fDelimiter:=Vrai ` Valeur par défaut
Au cas ou
`Nous avons un point (tester la virgule en Français).
: (($LAscii=46) & ($i<$LTextLength) & ($i>1))
` Vérifier le caractère précédent
$LPosition:=Position($tTextToParse?$i-1?;"1234567890")
Si ($LPosition>0) ` Le caractère précédent est un nombre
` Vérifier le caractère suivant
$LPosition:=Position($tTextToParse?$i+1?;"1234567890Xx@")
Si ($LPosition>0) ` Le caractère suivant est un nombre ou un caractère valide.
` Ce n'est pas un délimiteur, mais un point décimal (virgule en Français).
$fDelimiter:=Faux
Si (Longueur($sWord)<$LMaximumLength)
$sWord:=$sWord+Caractere($LAscii)
Fin de si
Fin de si
Fin de si
: (($LAscii=45) & ($i<$LTextLength)) `C'est peut-être un signe moins
` Vérifier le caractère suivant
$LPosition:=Position($tTextToParse?$i+1?;"1234567890")
Si ($LPosition>0) ` Le caractère suivant est un nombre
$fDelimiter:=Faux ` Ce n'est pas un tiret, mais un signe moins.
Si (Longueur($sWord)<$LMaximumLength)
$sWord:=$sWord+Caractere($LAscii)
Fin de si
Fin de si
: (($LAscii=95) & ($sWord="Prod")) `Nous avons un Prod suivi d'un underscore
`"Prod_", c'est un exemple d'exception
`Nous avons construit quelques mots "inventés" qui peuvent être inclus dans une
`recherche rapide
` Ex.
` Prod_MyWidget
` Prod_AcmeWidget
`Nous voulons inclure ces mots spéciaux comme valides dans le tableau des mots
`reconnus.
$fDelimiter:=Faux ` C'est le symbole d'une entrée de produits dans les mots
`Inutile de vérifier la longueur, il n'y a que 4 caractères
$sWord:=$sWord+Caractere($LAscii)
Fin de cas
Si ($fDelimiter)
Si ($i=$LTextLength) `C'est le dernier caractère, vérifions s'il fait partie du mot.
Si (Longueur($sWord)<$LMaximumLength) `Le mot est déjà trop long, on abandonne
`le dernier caractère.
Si (($LAscii>=48) & ($LAscii<=57)) | (($LAscii>=65) & ($LAscii<=90))
| (($LAscii>=97) & ($LAscii<=122)) | (($LAscii>=128)
& ($LAscii<=159))
$sWord:=$sWord+Caractere($LAscii)
Fin de si
Fin de si
Fin de si
Si (Longueur($sWord)>0)
`Prendre la valeur du mot à sauver
`limitée à la longueur maximum
$tWord:=Sous chaine($sWord;1;$LMaximumLength)
`Vérifier si le mot est dans le
`tableau des exceptions, sinon continuer
Si (Chercher dans tableau(<>atExceptions;$tWord)<1)
`Vérifier si le mot est dans le
`tableau courant, sinon continuer
Si (Chercher dans tableau($pArray->;$tWord)<1)
$LSizeOfArray:=$LSizeOfArray+1 ` Ajouter 1 à la taille tableau
TABLEAU TEXTE($pArray->;$LSizeOfArray) ` Redimensionner le tableau
$pArray->{$LSizeOfArray}:=$tWord ` Sauver le mot dans le tableaus
Fin de si
Fin de si
$sWord:=""
Fin de si
Fin de si
Sinon
Si (Longueur($sWord)<$LMaximumLength) `Quand il est trop long, l'ajout de
`caractères est sans importance
Si ((($LAscii<=159) | (($LAscii>=229) & ($LAscii<=244))) & ($LAscii#240)
& ($LAscii#96))
`N'ajouter que des caractères valides.
`Autoriser les caractères avec accents spéciaux, etc.
$sWord:=$sWord+Caractere($LAscii)
Fin de si
Fin de si
Fin de si
Fin de boucle
` Fin méthode
Une fois le tableau de mots uniques créé, il est transféré dans un blob VARIABLE VERS BLOB et sauvé dans le champ [BlocsTextes]Mots pour un usage ultérieur.
La table des clusters▲
Les clusters eux-mêmes sont stockés dans une table [Mots]. La table [Mots] a deux champs : le mot lui-même et un BLOB qui stocke le cluster sous forme de tableau booléen.
Conversion du tableau de mots en tableaux de cluster▲
Lorsqu'un nouvel enregistrement est saisi dans la base, la mise à jour des tableaux de cluster est simple. Chercher chaque mot dans le tableau des mots. Si le mot n'existe pas encore, créer un nouvel enregistrement et ajouter un tableau booléen au BLOB avec un seul élément fixé à Vrai. Si le mot existe, il faut lire le tableau booléen dans l'enregistrement et il faut augmenter la taille du tableau booléen de manière à ce qu'il ait au moins un élément de plus que le numéro d'enregistrement de l'enregistrement créé. (Cet élément supplémentaire permet la bonne création des ensembles.) Puis, mettre à Vrai l'élément de tableau correspondant au nouveau numéro d'enregistrement. Enfin, sauver le tableau booléen dans l'enregistrement. Ceci termine la tâche.
Modification des tableaux de cluster▲
Les nouveaux enregistrements sont simples. La tâche la plus complexe est à faire lorsqu'un enregistrement est modifié. Si du texte a été ajouté, la tâche reste simple. C'est comme l'ajout d'un nouvel enregistrement. Simplement, des [Mots] supplémentaires sont marqués pour retrouver l'enregistrement modifié. Cependant, les données sont fréquemment modifiées. Des mots sont supprimés, d'autres ajoutés. C'est ici que le tableau de mots stocké dans l'enregistrement [BlocsTextes] joue son rôle. Il contient tous les mots qui ont été sauvegardés auparavant. Ces mots sont lus dans le tableau atPrevWords. Comme auparavant, le tableau des mots courants est construit. Puis, les deux tableaux sont comparés. Les mots figurant dans les deux tableaux sont supprimés dans les deux tableaux, car ils ne représentent pas une modification.
À la fin, il existe deux tableaux : atPrevWords, qui contient tous les mots qui ne figurent plus dans l'enregistrement et atCurrentWords qui contient tous les mots ajoutés. Il devient alors nécessaire de supprimer les flags booléens de la table [Mots] pour chaque mot du tableau atPrevWords et, comme ci-dessus, de mettre les flags booléens pour atCurrentWords.
Ces tâches sont effectuées dans trois méthodes :
CLUSTER_Synchronize, CLUSTER_CompareArrays et CLUSTER_UpdateClusters.
Si (Faux)
` Méthode : CLUSTER_Synchronize (->Ptr)
` Created by: Kent Wilbur
` Objet: Cette méthode maintient les Clusters à jour
` $1 = pointeur sur la table de l'enregistrement courant à mettre à jour
Fin de si
C_POINTEUR($1;$pTable) ` Pointeur de table
` Déclaration des variables locales
C_POINTEUR($pWordsBLOBField)
C_POINTEUR($pBLOBField)
C_TEXTE(tText)
` Réaffectation pour plus de lisibilité
$pTable:=$1
TABLEAU TEXTE(atCurrentWords;0)
TABLEAU TEXTE(atPrevWords;0)
tText:=""
Au cas ou
: ($pTable=(->[BlocsTextes]))
tText:=[BlocsTextes]Titre+" "+[BlocsTextes]ZoneTexte `Veiller à séparer les valeurs à
`concaténer avec un délimiteur
$pWordsBLOBField:=->[Mots]EnsembleBlocTexte
$pBLOBField:=->[BlocsTextes]Mots
`On peut ajouter ici d'autres tables en ajoutant un autre BLOB à la table des [Mots]
`et en définissant les champs ci-dessus pour chaque table ajoutée
Fin de cas
Si (Taille BLOB($pBLOBField->)>0) ` Lire les mots précédents, s'il y en a
BLOB VERS VARIABLE($pBLOBField->;atPrevWords)
FIXER TAILLE BLOB($pBLOBField->;0)
Fin de si
CLUSTER_Text2Array (tText;->atCurrentWords) ` Mettre les mots courants dans un tableau
VARIABLE VERS BLOB(atCurrentWords;$pBLOBField->) `Sauver le tableau des mots courants
`pour une future mise à jour
STOCKER ENREGISTREMENT($pTable->)
CLUSTER_CompareArrays (->atPrevWords;->atCurrentWords) `Ceci retourne les mots figurant
`dans un seul des tableaux, ceux trouvés dans les deux sont éliminés.
CLUSTER_UpdateClusters ($pWordsBLOBField;Numero enregistrement($pTable->);
->atPrevWords;->atCurrentWords)
` Fin méthodeSi (Faux)
` Methode: CLUSTER_CompareArrays(ptr;ptr)
` Created by: Kent Wilbur
`$1 = pointeur sur le tableau des valeurs précédentes
`$2 = pointeur sur le tableau des valeurs courantes
`Objet : Comparer les deux tableaux et supprimer les éléments communs
`Il ne reste que les éléments différents entre les deux tableaux
Fin de si
` Déclaration des paramètres
C_POINTEUR($1;$pPrevious)
C_POINTEUR($2;$pCurrent)
` Déclaration des variables locales
C_ENTIER LONG($i)
C_ENTIER LONG($LPositionInArray)
` Réaffectation pour plus de lisibilité
$pPrevious:=$1
$pCurrent:=$2
Si (Taille tableau($pCurrent->)>0) ` Vérifier si le nouveau tableau a un élément
Boucle ($i;Taille tableau($pPrevious->);1;-1) `Nous allons supprimer des éléments
` nous devons donc opérer du dernier élément au premier
$LPositionInArray:=Chercher dans tableau($pCurrent->;$pPrevious->{$i})
`Le mot a été trouvé dans les deux tableaux, ce n'est donc pas un changement
Si ($LPositionInArray>0)
SUPPRIMER LIGNES($pCurrent->;$LPositionInArray)
SUPPRIMER LIGNES($pPrevious->;$i)
Fin de si
Fin de boucle
Fin de si
` Fin méthodeSi (Faux)
` Méthode: CLUSTER_UpdateClusters(ptr;long;ptr;ptr)
` Created by: Kent Wilbur
` Objet: Mise à jour de la table [Mots] pour le stockage des ensembles
` $1 = pointeur sur le champ BLOB dans [Mots]
`(en utilisant un pointeur, on peut gérer des ensembles sur plusieurs tables dans
`la même table [Mots] par l'ajout d'autres champs BLOB.
` $2 = entier long - numéro d'enregistrement
` $3 = pointeur sur le tableau des anciens mots à supprimer
` $4 = pointeur sur le tableau des mots à ajouter
Fin de si
` Déclaration des paramètres
C_POINTEUR($1;$pBLOBField)
C_ENTIER LONG($2;$LRecNum)
C_POINTEUR($3)
C_POINTEUR($4)
` Réaffectation pour plus de lisibilité
$pBLOBField:=$1
$LRecNum:=$2
` Déclaration des variables locales
TABLEAU TEXTE($atPreviousWords;0)
TABLEAU TEXTE($atCurrentWords;0)
C_BOOLEEN($fFlag)
C_ENTIER LONG($i;$j)
C_ENTIER LONG($LPostionInArray)
C_BLOB($oBlobSet)
COPIER TABLEAU($3->;$atPreviousWords)
COPIER TABLEAU($4->;$atCurrentWords)
LECTURE ECRITURE([Mots])
Boucle ($i;1;2)
REDUIRE SELECTION([Mots];0)
Au cas ou
: ($i=1)
$fFlag:=Faux `Mettre ce flag pour enlever ces mots des clusters
Si (Taille tableau($atPreviousWords)>0) `Ces mots sont à enlever des clusters
CHERCHER PAR TABLEAU([Mots]Mot;$atPreviousWords)
`Construire une sélection d'enregistrements d'après le tableau des mots précédents
Fin de si
: ($i=2)
$fFlag:=Vrai `Mettre ce flag pour ajouter ces mots aux clusters
Si (Taille tableau($atCurrentWords)>0) `Ces mots sont à ajouter aux clusters
CHERCHER PAR TABLEAU([Mots]Mot;$atCurrentWords)
Fin de si
Fin de cas
Boucle ($j;1;Enregistrements trouves([Mots]))
Tant que (Enregistrement verrouille([Mots])) `C'est la seule méthode où ils sont
` mis à jour, ils ne peuvent donc pas rester verrouillés longtemps
PROCESS_MyDelay (Numero du process courant;1)
CHARGER ENREGISTREMENT([Mots])
Fin tant que
TABLEAU BOOLEEN($afBoolean;0)
BLOB VERS VARIABLE($pBLOBField->;$afBoolean) `Charger les ensembles sauvegardés
Si (Taille tableau($afBoolean)<($LRecNum+1)) `Toujours s'assurer que le tableau
` a un élément supplémentaire pour que l'ensemble soit correctement sauvegardé
TABLEAU BOOLEEN($afBoolean;$LRecNum+1)
Fin de si
$afBoolean{$LRecNum}:=$fFlag ` Sauver le flag dans le bon élément du tableau
VARIABLE VERS BLOB($afBoolean;$pBLOBField->) ` Sauver les ensembles modifiés
STOCKER ENREGISTREMENT([Mots])
Si ($i=2)
$LPostionInArray:=Chercher dans tableau($atCurrentWords;[Mots]Mot)
Si ($LPostionInArray>0)
SUPPRIMER LIGNES($atCurrentWords;$LPostionInArray)
`Ce mot a été mis à jour, l'enlever du tableau
Fin de si
Fin de si
ENREGISTREMENT SUIVANT([Mots])
Fin de boucle
Fin de boucle
Si (Taille tableau($atCurrentWords)>0) `S'il en reste, ils sont forcément nouveaux
TABLEAU BOOLEEN($afBoolean;0)
TABLEAU BOOLEEN($afBoolean;$LRecNum+1) ` Créer un tableau booléen
` avec un élément de plus que le numéro d'enregistrement courant
$afBoolean{0}:=Faux
$afBoolean{$LRecNum}:=Vrai ` Faire de cet enregistrement le seul enregistrement de l'ensemble
VARIABLE VERS BLOB($afBoolean;$oBlobSet)
Boucle ($i;1;Taille tableau($atCurrentWords)) `Créer un enregistrement pour chaque
` mot restant, avec le même ensemble.
CREER ENREGISTREMENT([Mots])
[Mots]Mot:=$atCurrentWords{$i}
$pBLOBField->:=$oBlobSet
STOCKER ENREGISTREMENT([Mots])
Fin de boucle
Fin de si
LECTURE SEULEMENT([Mots])
LIBERER ENREGISTREMENT([Mots])
` Fin méthodeOù faut-il mettre à jour le cluster ?▲
De toute évidence, chaque fois qu'un enregistrement est créé ou modifié. Mais, où écrire le code ? Ma réponse à cette question est toujours « ça dépend ». Faites-vous des imports ? Ajoutez-vous des enregistrements via SOAP ou le Web ? Le fait d'attendre la mise à jour des clusters lors de la sauvegarde d'un enregistrement aura-t-il une incidence pour l'utilisateur ?
En fonction des réponses, vous pourriez le faire dans une Méthode formulaire ou dans une Méthode projet. Mais, c'est mieux dans un Trigger parce qu'il ne peut pas être contourné. Cependant, avec le code dans un Trigger, la sauvegarde d'un enregistrement peut prendre beaucoup de temps.
Dans cette base, j'ai choisi d'exécuter le code de mise à jour des clusters dans son propre process. J'utilise des tableaux interprocess pour indiquer le numéro de table et le numéro d'enregistrement de chaque enregistrement qui doit mettre à jour le cluster. Dans le Trigger, Sur sauvegarde enregistrement, j'ajoute l'information nécessaire dans les tableaux interprocess et je réveille le process de mise à jour, si besoin. Vous vous demandez pourquoi le numéro de table. En réalité, ce code est simplifié. Dans un véritable environnement de production, je pourrais avoir plus d'une table à ajouter au cluster. Chaque table pourrait avoir son propre champ BLOB dans la table [Mots]. Ainsi, le numéro de table est une simple indication de ce que vous pourriez faire.
Le Trigger de [BlocsTextes] déclenche toute l'action.
Si (Faux)
` Trigger: [BlocsTextes]
` Created by: Kent Wilbur
` Objet :
Fin de si
` Déclaration des paramètres
C_ENTIER LONG($0)
` Déclaration des variables locales
C_ENTIER LONG($LDatabaseEvent)
C_ENTIER LONG($LSizeOfArray)
` Réaffectation pour plus de lisibilité
$LDatabaseEvent:=Evenement moteur
$0:=0
Au cas ou
: ($LDatabaseEvent=Sur sauvegarde enregistrement ) | ($LDatabaseEvent=Sur sauvegarde nouvel enreg )
Tant que (Semaphore("$ModClusterArray"))
PROCESS_MyDelay (Numero du process courant;1)
Fin tant que
$LSizeOfArray:=Taille tableau(<>CLUSTER_LTable)+1
INSERER LIGNES(<>CLUSTER_LTable;$LSizeOfArray)
INSERER LIGNES(<>CLUSTER_LRecordNum;$LSizeOfArray)
<>CLUSTER_LTable{$LSizeOfArray}:=Table(->[BlocsTextes])
<>CLUSTER_LRecordNum{$LSizeOfArray}:=Numero enregistrement([BlocsTextes])
EFFACER SEMAPHORE("$ModClusterArray")
CLUSTER_ResumeProcessing
: ($LDatabaseEvent=Sur suppression enregistrement ) `Ceci va vraiment ralentir et
`bloquer la base, c'est donc à éviter
`Essayez plutôt de le gérer dans votre propre code plutôt qu'ici.
`Ce code va annuler la suppression de manière à maintenir l'intégrité du cluster.
Si (Longueur([BlocsTextes]ZoneTexte+[BlocsTextes]Titre)>0)
$0:=-15111
Fin de si
Fin de cas
`Fin du trigger
La méthode CLUSTER_ResumeProcessings gère l'autre process. Si le process est suspendu, elle le réactive. S'il a été détruit ou n'existe pas, elle le lance.
Si (Faux)
` Méthode : CLUSTER_ResumeProcessing
` Created by: Kent Wilbur
` Objet : Lance ou réactive le process de traitement du cluster
Fin de si
C_ENTIER LONG($LPid)
C_ENTIER LONG($LProcessState)
$LPid:=Chercher process("Maintain Clusters")
$LProcessState:=Statut du process($LPid)
Au cas ou
: ($LProcessState=Suspendu )
REACTIVER PROCESS($LPid)
: ($LProcessState=Détruit ) | ($LPid=0)
$LPid:=Nouveau process("P_MaintainClusters";32000;"Maintain Clusters")
Sinon
`Le process est déjà en cours, rien d'autre à faire
Fin de cas
` Fin méthode
Comparée au code que nous avons déjà regardé, la méthode P_MaintainClusters est assez simple. Elle vérifie les tableaux et met à jour les clusters en fonction des valeurs des tableaux interprocess.
Si (Faux)
` Method: P_MaintainClusters
` Created by: Kent Wilbur
` Objet: Maintenir les clusters de la table [Mots]
Fin de si
C_ENTIER LONG($LRecordNumber)
C_POINTEUR($pTable)
LECTURE SEULEMENT(*)
Repeter
SUSPENDRE PROCESS(Numero du process courant)
Si (Taille tableau(<>CLUSTER_LTable)>0) ` S'il y a quelque chose à faire
Repeter
Tant que (Semaphore("$ModClusterArray"))
PROCESS_MyDelay (Numero du process courant;1)
Fin tant que
$pTable:=Table(<>CLUSTER_LTable{1})
$LRecordNumber:=<>CLUSTER_LRecordNum{1}
SUPPRIMER LIGNES(<>CLUSTER_LTable;1)
SUPPRIMER LIGNES(<>CLUSTER_LRecordNum;1)
EFFACER SEMAPHORE("$ModClusterArray")
ALLER A ENREGISTREMENT($pTable->;$LRecordNumber)
CLUSTER_Synchronize ($pTable) ` Mettre à jour les clusters
LIBERER ENREGISTREMENT($pTable->)
Jusque (Taille tableau(<>CLUSTER_LTable)=0) ` Continuer en cas d'ajout en cours d'exécution
Fin de si
Jusque (<>fQuit)
` Fin méthodeSuppression d'un enregistrement▲
Lorsqu'un enregistrement est supprimé, il faut aussi mettre à jour les clusters. Si vous avez lu attentivement le code ci-dessus, vous avez remarqué que je n'ai pas mis à jour les clusters dans le trigger. Ceci pourrait éventuellement poser des problèmes avec d'autres utilisateurs. Au contraire, lors de la suppression d'un enregistrement, tous les mots du tableau atPrevWord doivent être supprimés et aucun n'est ajouté. J'effectue cela dans le code de suppression de l'enregistrement, avant l'appel au trigger. Mon trigger vérifie la présence d'une valeur dans le titre ou dans la zone texte. Si une de ces valeurs existe, la suppression est annulée parce que le code associé à la suppression n'a pas été exécuté. Voici un court extrait de la méthode objet du bouton de suppression bDelete :
Boucle ($i;1;Taille tableau($aLRecNo))
ALLER A ENREGISTREMENT(Table du formulaire courant->;$aLRecNo{$i})
[BlocsTextes]Titre:=""
[BlocsTextes]ZoneTexte:=""
CLUSTER_Synchronize (Table du formulaire courant)
SUPPRIMER ENREGISTREMENT(Table du formulaire courant->)
Fin de boucleRécupération par marqueurs et compactage de la base▲
Il arrive parfois qu'un incident se produise et que la base ait besoin d'une réparation. Le concept des clusters est fondé sur les numéros d'enregistrements. Lorsqu'une base subit une réparation par marqueurs ou un compactage, les numéros d'enregistrements peuvent être modifiés. C'est pourquoi il faut reconstruire complètement les clusters. La méthode suivante va reconstruire les clusters comme si tous les enregistrements étaient nouveaux.
Faites attention, car cette méthode échouera si elle rencontre un enregistrement verrouillé. C'est pourquoi il faut la faire tourner avec un seul utilisateur en ligne ou la réécrire pour gérer les conflits.
Si (Faux)
` Méthode: E_RebuildAllClusters
` Created by: Kent Wilbur
` Objet : En cas de catastrophe, ceci reconstruira les clusters depuis le début.
`S'assurer qu'il n'y a qu'un utilisateur en ligne pour
`qu'il n'y ait pas d'enregistrements verrouillés
`ou réécrire la méthode pour qu'elle gère les enregistrements verrouillés,
`notamment par SUPPRIMER SELECTION et APPLIQUER A SELECTION
Fin de si
` Déclaration des variables locales
C_ENTIER LONG($i)
C_BLOB($oEmptyBlob)
LECTURE ECRITURE([Mots])
TOUT SELECTIONNER([Mots])
SUPPRIMER SELECTION([Mots]) ` Tout supprimer, on recommence depuis le début
LECTURE ECRITURE([BlocsTextes])
TOUT SELECTIONNER([BlocsTextes])
FIXER TAILLE BLOB($oEmptyBlob;0) ` S'assurer que le blob est vide
`Eliminer tous les mots existants pour que tous les
`enregistrements soient traités comme "nouveaux"
APPLIQUER A SELECTION([BlocsTextes];[BlocsTextes]Mots:=$oEmptyBlob)
`Le process de mise à jour ajoutera l'enregistrement aux tableaux à actualiser
LECTURE SEULEMENT([BlocsTextes])
` Fin méthodeRésumé▲
Dans la deuxième partie nous verrons l'usage des clusters pour rechercher des données. Nous étudierons comment différentes requêtes peuvent être utilisées pour améliorer la performance. Pour le moment, regardez simplement le code pour créer et maintenir les clusters. N'oubliez pas qu'un cluster n'améliorera pas les performances lorsqu'un champ monovalué indexé est le seul critère de recherche. Mais ils sont idéaux pour les recherches fréquentes par mot-clés, par contenus ou les recherches complexes multichamps.
Base exemple▲
Télécharger la base exemple.