


I. Résumé ♪▲
Les commandes XML de 4e Dimension 2003 permettent d’analyser et valider du XML, de naviguer dans les arbres XML et d’extraire les valeurs des éléments XML et de leurs attributs. Cette note technique décrit un composant qui ajoute quelques utilitaires pratiques aux commandes natives de 4D 2003.
II. Description de la méthode▲
- xutil_CountOccurrences compte combien de fois est présent un élément ;
- xutil_ElementExists retourne Vrai si un élément existe ;
- xutil_GetValue retourne la valeur d’un élément simple en texte ;
- xutil_StripWhitespace Retire les caractères blancs, comme défini par XML, d’un bloc de texte.
Outre la fourniture de fonctionnalités utiles, le code du composant XML Utilities procure des exemples sur la manière de travailler avec les commandes XML de 4e Dimension 2003. Les méthodes sont incluses à la fois dans une base de données en code source ouvert pour une lecture directe et sous forme de composant installable avec 4D Insider. Cette note technique explique d’abord l’approche utilisée par le code et fournit ensuite des exemples et une documentation de chaque fonction.
III. Les paramètres attendus▲
La plupart des fonctions du composant XML_Utilities attendent des références et des noms d’éléments en paramètres. Voici quelques règles et rappels sur ces types d’arguments :
- les références d’éléments XML sont des chaînes de 16 caractères retournées par le parseur XML de 4e Dimension et les commandes de navigation. Appelez Analyser source XML ou Analyser variable XML pour analyser l’XML et passez la référence retournée par 4e Dimension aux fonctions d’XML_Utilities ;
- afin de libérer la mémoire, chaque appel Analyser source XML ou Analyser variable XML devrait se terminer par un appel à la commande FERMER XML une fois que l’arbre XML construit n’est plus nécessaire. Les fonctions du composant XML_Utilities n’appellent pas FERMER XML ;
- à la différence des noms 4e Dimension, les noms XML sont sensibles à la casse. En conséquence, les noms suivants sont différents : Nom_famille et Nom_Famille. Le composant XML_Utilities effectue des comparaisons sur les noms en tenant compte de la casse ;
- les fonctions du composant XML_Utilities ne supportent pas les jokers dans les noms XML. En conséquence, les deux noms suivants ne sont pas identiques : nom_famille et nom_fam@.
IV. Échantillon XML▲
L’échantillon XML listé ci-dessous est utilisé dans les exemples présentés dans cette note technique :
<?xml version="1.0" encoding="ISO-8859-1"?>
<Root>W
<Descendant_1>A
<Descendant_2>L</Descendant_2>
<Descendant_2>K</Descendant_2>
<Descendant_2>I
<Descendant_3>N</Descendant_3>
</Descendant_2>
</Descendant_1>
<Descendant_1>G</Descendant_1>
</Root>La table ci-dessous résume les résultats de l’application des fonctions du composant XML_Utilities à la structure XML précédente :
|
Element |
Nombre d’occurrences |
Numéro de l’occurrence |
Existe |
Valeur nettoyée de la première occurrence |
|---|---|---|---|---|
|
Root |
1 |
1 |
Vrai |
W |
|
Descendant_1 |
2 |
1 |
Vrai |
A |
|
Descendant_1 |
2 |
2 |
Vrai |
G |
|
Descendant_2 |
3 |
1 |
Vrai |
L |
|
Descendant_2 |
3 |
2 |
Vrai |
K |
|
Descendant_2 |
3 |
3 |
Vrai |
I |
|
Descendant_3 |
1 |
1 |
Vrai |
N |
|
Descendant_4 |
0 |
1 |
Faux |
Chaîne vide |
V. À propos des arbres XML et de l’ordre des éléments▲
Les commandes XML de 4D 2003 analysent le XML sous forme d’arbres. Il existe plusieurs chemins et directions pour se déplacer dans les arbres XML : haut-vers-le-bas, bas-vers-le-haut, et par niveau, ou bien de gauche à droite ou de droite à gauche.
Les méthodes du composant XML_Utilities, comme presque tous les exemples de 4e Dimension, parcourent l’arbre XML du haut vers le bas, en utilisant la direction de gauche à droite. Ce style de parcours d’arbre est habituellement appelé « preorder traversal » dans les livres d’algorithme. Cette stratégie est plus facile à visualiser en utilisant une illustration simplifiée de l’arbre XML produit par l’analyse de l’échantillon XML présenté plus haut :
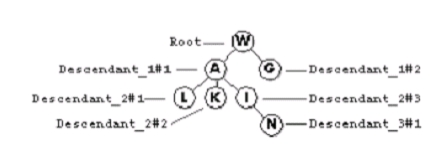
Le code du composant XML_Utilities visite les nœuds suivant la séquence décrite dans la table ci-dessous :
|
Nom du nœud |
Valeur nettoyée |
Numéro d’occurrence |
|---|---|---|
|
Root |
W |
1 |
|
Descendant_1 |
A |
1 |
|
Descendant_2 |
L |
1 |
|
Descendant_2 |
K |
2 |
|
Descendant_2 |
I |
3 |
|
Descendant_3 |
N |
1 |
|
Descendant_1 |
G |
2 |
xutil_CountOccurrences
xutil_CountOccurrences (elementRef;nomCible{;premierAppel}) -> Entier long|
Paramètre |
Type |
Description |
|---|---|---|
|
elementRef |
Alpha (16) |
-> référence d’un élément XML à utiliser comme point de départ |
|
nomCible |
Texte |
-> Nom de l’élément à retrouver |
|
premierAppel |
Booléen |
-> Est-ce le premier appel à la méthode ? |
|
nombre |
Entier Long |
<- Nombre d’éléments correspondants |
La fonction xutil_CountOccurrences compte combien de fois un élément du nom spécifié apparaît dans un arbre XML. Le résultat de l’exemple d’appel ci-dessous appliqué à la structure XML listée plus haut est 3 :
2.
3.
4.
5.
6.
7.
C_ALPHA(16;$xmlref)
$xmlref:=Analyser variable XML($sample_xml)
C_ENTIER LONG($count)
$count:=xutil_CountOccurrences ($xmlref;"Descendant_2")
FERMER XML($xmlref)
L’argument premierAppel est utilisé automatiquement en interne pour gérer le code récursif. Normalement, il n’y a aucune raison de passer ce paramètre lors d’un appel à xutil_CountOccurrences.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
C_ENTIER LONG($0;$count)
C_ALPHA(16;$1;$xmlref)
C_TEXTE($2;$targetName_t)
C_BOOLEEN($3;$isFirstCallInChain_b)
$xmlref:=$1
$targetName_t:=$2
$isFirstCallInChain_b:=Vrai
Si (Nombre de parametres>2)
$isFirstCallInChain_b:=$3
Fin de si
$count:=0
Si ($isFirstCallInChain_b)
C_ENTIER LONG(OK)
OK:=1 ` fixe la valeur de la variable de contrôle avant d’entrer
`dans la boucle pour la première fois
Sinon
$xmlref:=Lire premier element XML ($xmlref)
Fin de si
Repeter
Tant que (OK=1)
C_TEXTE($currentName_t)
$currentName_t:=""
LIRE NOM ELEMENT XML ($xmlref;$currentName_t)
Si (xutilStringsAreEqual ($currentName_t;$targetName_t))
$count:=$count+1
$xmlref:=Lire element XML suivant ($xmlref)
Sinon
$count:=$count+xutil_CountOccurrences ($xmlref;$targetName_t;Faux)
$xmlref:=Lire element XML suivant ($xmlref)
Fin de si
Fin tant que
Jusque (OK=0)
$0:=$count
Une note sur la récursivité▲
La fonction xutil_CountOccurrences s’appelle elle-même de manière récursive pour inspecter chaque branche de l’arbre XML parcouru. Si la récursivité est l’approche la plus répandue dans ce type de navigation, elle n’est pas la seule possibilité. En interne, la récursivité fonctionne en créant une pile des appels de méthode, chacune avec ses arguments distincts (valeurs de paramètres). Le même jeu de nœuds peut être visité à l’aide de boucles et d’une pile maintenue à la main, typiquement en recourant à un tableau 4e Dimension.
xutil_ElementExists
Description
xutil_ElementExists (elementRef ;nomCible) -> Booleen|
Paramètre |
Type |
Description |
|---|---|---|
|
elementRef |
Alpha (16) |
-> référence de l’élément XML à utiliser comme point de départ |
|
nomCible |
Texte |
-> nom de l’élément à rechercher |
|
siExiste |
Booleen |
Vrai si l’élément existe, Faux sinon |
La fonction xutil_ElementExists teste si un élément du nom spécifié apparaît dans un arbre XML. Le résultat du code exemple ci-dessous est Faux si on l’applique à l’extrait XML cité plus haut :
2.
3.
4.
5.
6.
7.
C_ALPHA(16;$xmlref)
$xmlref:=Analyser variable XML($sample_xml)
C_ENTIER LONG($count)
$count:=xutil_ElementExists ($xmlref;"first_name")
FERMER XML($xmlref)
Code source :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
C_BOOLEEN($0;$elementExists_b)
C_ALPHA(16;$1;$xmlref)
C_TEXTE($2;$targetName_t)
$xmlref:=$1
$targetName_t:=$2
$elementExists_b:=Faux
C_ENTIER LONG$count)
$count:=xutil_CountOccurrences ($xmlref;$targetName_t)
Si ($count>0)
$elementExists_b:=Vrai
Sinon
$elementExists_b:=Faux
Fin de si
$0:=$elementExists_b
xutil_GetValue
Description
xutil_GetValue (elementRef;nomCible{;index{;nettoyer{;premierAppel}}}) -> Texte|
Paramètre |
Type |
Description |
|---|---|---|
|
ElementRef |
Alpha (16) |
-> référence de l’élément XML à utiliser comme point de départ |
|
nomCible |
Texte |
-> Nom de l’élément à rechercher |
|
index |
Entier Long |
-> ordre de l’occurrence de laquelle lire la valeur |
|
nettoyer |
Booleen |
-> nettoyer les espaces blancs de la valeur de l’élément ? |
|
premierAppel |
Booleen |
-> s’agit-il du premier appel à la méthode ? |
|
valeur |
Texte |
<- valeur de l’élément correspondant ou chaîne vide |
La fonction xutil_GetValue retourne la valeur de l’élément dont le nom est spécifié ou une chaîne vide si l’élément n’est pas présent.
Le paramètre optionnel index permet de demander à lire une occurrence précise d’un élément. Une valeur par défaut de 1 est utilisée lorsque l’argument optionnel n’est pas passé. Le résultat de l’exemple de code ci-dessous est la valeur « K » pour l’extrait XML cité plus haut :
2.
3.
4.
5.
6.
7.
C_ALPHA(16;$xmlref)
$xmlref:=Analyser variable XML ($sample_xml)
C_ENTIER LONG($count)
$count:=xutil_GetValue ($xmlref;"Descendant_2";2)
FERMER XML($xmlref)
Le paramètre optionnel nettoyer contrôle l’élimination des espaces blancs encadrant la valeur de l’élément. Une valeur par défaut à Faux est utilisée si ce paramètre optionnel n’est pas précisé. Lorsque nettoyer est fixé à Vrai, les espaces blancs encadrant la valeur sont supprimés avant le retour de résultat ; lorsque nettoyer est fixé à Faux, les espaces blancs sont préservés. Reportez-vous xutil_StripWhitespace dans les pages suivantes pour plus d’information. L’argument premierAppel est utilisé automatiquement en interne pour gérer le code récursif. Normalement, il n’y a aucune raison de passer ce paramètre lors d’un appel à xutil_GetValue.
Code source :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
C_TEXTE($0;$resultValue_t)
C_ALPHA(16;$1;$xmlref)
C_TEXTE($2;$targetName_t)
C_ENTIER LONG($elementToFind_index)
C_BOOLEEN($4;$cleanValue_b)
C_BOOLEEN($5;$isFirstCallInChain_b)
$xmlref:=$1
$targetName_t:=$2
C_ENTIER LONG($parameters_count)
$parameters_count:=Nombre de parametres
Au cas ou ` Remplit les paramètres optionnels avec les valeurs passées ou celles par défaut
: ($parameters_count<3)
$elementToFind_index:=1
$cleanValue_b:=Faux
$isFirstCallInChain_b:=Vrai
: ($parameters_count<4)
$elementToFind_index:=$3
$cleanValue_b:=Faux
$isFirstCallInChain_b:=Vrai
: ($parameters_count<5)
$elementToFind_index:=$3
$cleanValue_b:=$4
$isFirstCallInChain_b:=Vrai
: ($parameters_count<6)
$elementToFind_index:=$3
$cleanValue_b:=$4
$isFirstCallInChain_b:=$5
Fin de cas
$resultValue_t:=""
Si ($isFirstCallInChain_b)
C_BOOLEEN(xutil_GetValue_stop)
xutil_GetValue_stop:=Faux
C_ENTIER LONG(xutil_GetValueMatches_count)
xutil_GetValueMatches_count:=0
C_ENTIER LONG(OK)
OK:=1 ` fixe la valeur de la variable de contrôle avant d’entrer dans la boucle pour la première fois
Sinon
$xmlref:=Lire premier element XML ($xmlref)
Fin de si
Repeter
Tant que ((OK=1) & (xutil_GetValue_stop=Faux))
C_TEXTE($currentValue_t)
$currentName_t:=""
$currentValue_t:=""
LIRE NOM ELEMENT XML ($xmlref;$currentName_t)
LIRE VALEUR ELEMENT XML ($xmlref;$currentValue_t)
Si (xutilStringsAreEqual ($currentName_t;$targetName_t))
xutil_GetValueMatches_count:=xutil_GetValueMatches_count+1
Si (xutil_GetValueMatches_count=$elementToFind_index)
$resultValue_t:=$currentValue_t
xutil_GetValue_stop:=Vrai
OK:=0
Fin de si
$xmlref:=Lire element XML suivant ($xmlref)
Sinon
$resultValue_t:=xutil_GetValue
($xmlref;$targetName_t;$elementToFind_index;$cleanValue_b;False)
$xmlref:=Lire element XML suivant ($xmlref)
Fin de si
Fin tant que
Jusque ((OK=0) | xutil_GetValue_stop)
Si ($cleanValue_b)
$resultValue_t:=xutil_StripWhitespace ($resultValue_t)
Fin de si
$0:=$resultValue_t
xutil_StripWhitespace
xutil_StripWhitespace (source) -> Texte|
Paramètre |
Type |
Description |
|---|---|---|
|
source |
Texte |
-> texte dont les espaces blancs doivent être retirés |
|
Résultat |
Texte |
<- le texte initial dont les espaces blancs ont été retirés |
XML définit quatre caractères comme espaces blancs, listés dans le tableau ci-dessous :
|
Nom |
Code ascii |
Hexa |
|---|---|---|
|
Tab |
9 |
09 |
|
Line feed (retour à la ligne) |
10 |
0A |
|
Carriage return (retour chariot) |
13 |
0D |
|
Espace |
32 |
20 |
Les espaces blancs améliorent grandement la lisibilité des documents XML, mais sont souvent indésirables lors du travail avec les valeurs des éléments XML. Par exemple, la valeur de la première instance du Descendant_1 dans l’extrait XML cité plus haut est longue de 16 caractères. La voici avec les noms des espaces blancs mentionnés explicitement :
<b>A<retour_chariot></b>
<b><retour_chariot ></b>
<b><tab> <tab> <retour_chariot ></b>
<b><retour_chariot ></b>
<b><tab> <tab> <retour_chariot ></b>
<b><retour_chariot ></b>
<b><tab> <tab> <retour_chariot ></b>
<b><retour_chariot ></b>
<b><tab></b>La valeur nettoyée de cet élément est le seul caractère « A ».
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
C_TEXTE($0;$result_t)
C_TEXTE($1;$source_t)
$source_t:=$1
$result_t:=""
` -------------------------------------------------------------------------------------------------
` Prépare un tableau de tous les caractères définis comme espaces blancs
` -------------------------------------------------------------------------------------------------
TABLEAU ENTIER LONG($whitespace_al;4)
$whitespace_al{1}:=Tabulation
$whitespace_al{2}:=Retour à la ligne
$whitespace_al{3}:=Retour chariot
$whitespace_al{4}:=Espacement
C_ENTIER LONG($firstCharacter_index)
C_ENTIER LONG($lastCharacter_index)
$firstCharacter_index:=0
$lastCharacter_index:=0
` ---------------------------------------------------------
` Trouver le premier caractère non espace blanc
` ---------------------------------------------------------
C_ENTIER LONG($length)
C_ ENTIER LONG($index)
C_ ENTIER LONG($element)
C_ ENTIER LONG($ascii)
$length:=Longueur($source_t)
$index:=0
$element:=0
$ascii:=0
C_BOOLEEN($done)
$done:=Faux
Repeter
$index:=$index+1
Si ($index>$length)
$done:=Vrai
Sinon
$ascii:=Code ascii($source_t=$index=)
$element:=Chercher dans tableau($whitespace_al;$ascii)
Si ($element<0)
` Le caractère testé n’est pas un espace blanc : c’est ce que nous cherchions
$firstCharacter_index:=$index
$done:=Vrai
Fin de si
Fin de si
Jusque ($done)
` ---------------------------------------------------------
` Trouver le dernier caractère non espace blanc
` ---------------------------------------------------------
C_ENTIER LONG($index)
C_ENTIER LONG($element)
$index:=Longueur($source_t)+1
$element:=0
C_BOOLEEN($done)
$done:=Faux
Repeter ` marche arrière à travers la chaîne à la recherche du dernier caractère non espace blanc
$index:=$index-1
Si ($index=0)
$done:=Vrai
Sinon
$ascii:=Ascii($source_t=$index=)
$element:=Chercher dans tableau($whitespace_al;$ascii)
Si ($element<0)
` Le caractère testé n’est pas un espace blanc : c’est ce que nous cherchions
$lastCharacter_index:=$index
$done:=True
Fin de si
Fin de si
Jusque ($done)
` ---------------------------------------------------------
` Nettoye la chaîne source.
` ---------------------------------------------------------
C_ENTIER LONG($result_length)
$result_length:=$lastCharacter_index-$firstCharacter_index+1
Au cas ou
: ($lastCharacter_index=0)
$result_t:=""
: ($firstCharacter_index=0)
$result_t:=""
: ($result_length<1)
$result_t:=""
Sinon
$result_t:=Sous chaine($source_t;$firstCharacter_index;$result_length)
Fin de cas
$0:=$result_t
xutilStringsAreEqual
Le composant inclut également une méthode privée qui compare l’égalité de deux chaînes. Ce code est nécessaire car le système de comparaison de chaîne natif à 4e Dimension, dépendant des réglages de langue, ignore les différences de casse et les caractères diacritiques. Les chaînes XML sont toujours sensibles à la casse. Le tableau ci-dessous compare la manière dont 4e Dimension et XML considèrent l’équivalence de quelques échantillons de chaînes :
|
Chaîne exemple |
Chaîne de comparaison |
Égalité dans 4D |
Égalité en XML |
|---|---|---|---|
|
a-b-c-d-e |
a-b-c-d-e |
Oui |
Oui |
|
a-b-c-d-e |
a-b-c-d-E |
Oui |
Non |
|
a-b-c-d-e |
a-b-c-d-é |
Oui |
Non |
|
a-b-c-d-e |
A-B-C-D-E |
Oui |
Non |
La méthode xutilStringsAreEqual compare des chaînes caractère par caractère en se fondant sur le code ascii pour retourner un résultat compatible avec les règles des noms XML.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
C_BOOLEEN($0;$StringsAreEqual_b)
C_TEXTE($1;$baseString_t)
C_TEXTE($2;$comparisonString_t)
$baseString_t:=$1
$comparisonString_t:=$2
$StringsAreEqual_b:=Faux
Au cas ou
: ($baseString_t#$comparisonString_t) ` Echec dans la comparaison native par 4D
$StringsAreEqual_b:=Faux
: ($baseString_t="") ` Les deux chaînes sont vides
$StringsAreEqual_b:=Vrai
Sinon
` Effectue une comparaison octet par octet
C_ENTIER LONG($length)
C_ENTIER LONG($index)
C_BOOLEEN($continue)
$length:=Longueur($baseString_t)
$index:=1 ` les chaines ne sont pas valides
C_ENTIER LONG($base_ascii)
C_ENTIER LONG($comparison_ascii)
$continue:=Vrai
$StringsAreEqual_b:=Vrai
Tant que ($continue)
$base_ascii:=Code ascii($baseString_t=$index=)
$comparison_ascii:=Code ascii($comparisonString_t=$index=)
Au cas ou
: ($base_ascii=$comparison_ascii)
$index:=$index+1
: ($base_ascii#$comparison_ascii)
$StringsAreEqual_b:=Faux
$continue:=Faux
Fin de cas
Si ($index>$length)
$continue:=Faux
Fin de si
Fin tant que
Fin de cas
$0:=$StringsAreEqual_b
VI. Bases exemples▲
Téléchargez les bases exemples :
base exemple Mac
base exemple Win