



I. Introduction▲
Les index sont des mécanismes indispensables pour optimiser le fonctionnement de la base de données notamment pour les opérations de tri ou de recherche d'enregistrements.
Cependant, ce sont des objets qui peuvent être abîmés pour diverses raisons ce qui peut corrompre la base de données ou les résultats fournis.
Dans cette note technique, nous allons étudier des moyens de détecter des erreurs sur les index, et ceci sans quitter la base de données pour utiliser un utilitaire de contrôle.
Le principe d'un index est de recopier une information contenue dans un enregistrement en l'organisant spécialement en vue d'optimiser les recherches et les tris.
Un index est grosso modo une liste des valeurs possibles pour un champ d'une table. Pour chaque valeur (donc pour chaque enregistrement) est associé le numéro de l'enregistrement dans lequel figure celle-ci. Libre ensuite au concepteur de l'index d'organiser cette liste pour que son utilisation soit optimisée au mieux. Dans le cas de 4e Dimension il s'agit d'un arbre balancé (B-Tree) .
Comme il s'agit d'une redondance d'information, il est primordial que les données de l'index soient synchrones avec les données originales contenues dans les enregistrements. Heureusement ceci ne pose aucun problème dans la majorité des cas de fonctionnements normaux. Cependant il arrive que l'index s'abîme pour diverses raisons comme, par exemple, son écriture sur un secteur endommagé du disque dur ou autre… Notre propos n'est pas de trouver les causes des défaillances, mais de prévenir les ennuis éventuellement engendrés en proposant une méthodologie de détection.
Au cours de cette note technique, nous allons donc vous proposer des méthodes en code 4D permettant de détecter les éventuelles erreurs. Contrairement à des outils tels que 4D Tools, les méthodes pourront être exécutées en cours d'utilisation de la base. Il ne sera donc pas nécessaire d'arrêter la base pour contrôler les index.
La base exemple est accompagnée d'une série de fichiers de données :
- un fichier nommé « NT_Index_Correct.4DD » sans problèmes particuliers ;
- des fichiers ayant chacun un type de problème traité par les méthodes de cette note technique.
II. Base de test▲
La base de test est très simple ! En effet elle ne propose qu'une table contenant des données :
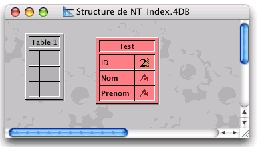
Les données sont générées via la méthode Creer_Enregistrement :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
$lettre:="ABCDEFGHIJKLMNOPQRSTUVWXYZ"
Boucle ($i;1;1000;1)
CREER ENREGISTREMENT([Test])
[Test]ID:=Numerotation automatique([Test])
$,car:=$i%26+1
[Test]Nom:=$lettre=$,car=*10
[Test]Prenom:=Minusc($lettre=27-$,car=*10)
STOCKER ENREGISTREMENT([Test])
Fin de boucle
Les 1000 enregistrements contiennent des noms tout en majuscules et des prénoms tout en minuscules. Les champs sont simplement constitués d'une série de 10 lettres identiques.
Ce choix simple est suffisant pour les tests et permet de créer des erreurs dans les fichiers de données plus facilement. En effet les fichiers de données abîmés ont été corrompus manuellement par modification des informations directement avec un éditeur hexadécimal. C'est effectivement la meilleure manière d'être certains d'obtenir des fichiers intéressants pour nos tests !
Toutes les erreurs ont été générées sur l'index des noms.
III. Mise en place des méthodes de test▲
La base fournie avec la note technique propose une série de méthodes préfixées « CIC » pour « Contrôle des Index en Cours d'utilisation ».
Pour contrôler un index, il suffit de passer la ligne suivante que l'on trouve dans la méthode Test_Index_Nom :
CIC_Controle_Index (->[Test]Nom)
Cette méthode réalise les opérations de contrôle et affiche une alerte en cas de problème. Voici le code de la méthode CIC_Contrôle_Index :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
C_POINTEUR($1)
CIC_Controle_Phase_Init ($1)
Au cas ou
: (CIC_Controle_Phase_1 )
: (CIC_Controle_Phase_2 )
: (CIC_Controle_Phase_3 )
Fin de cas
Si (cic_error#0)
ALERTE(cic_error_text+" ("+Chaine(cic_error)+")")
Fin de si
Dans un premier temps une phase d'initialisation est effectuée. C'est l'objet de la méthode CIC_Contrôle_Phase_Init.
Ensuite une série de contrôles est réalisée. C'est l'objet des méthodes CIC_Contrôle_Phase_x qui retourne Faux si aucune erreur n'est rencontrée, et Vrai dans les autres cas. Les méthodes ainsi combinées au sein d'une structure 'Au cas ou' comme dans le code précédent, ne sont exécutées que si la méthode précédente n'a pas trouvé d'erreur. Autrement dit dès qu'une erreur est détectée les contrôles s'interrompent. Ceci permet de ne pas faire des contrôles inutiles et donc d'obtenir une réponse le plus rapidement possible. Nous partons en effet du principe qu'une seule erreur suffit à déclarer l'index corrompu.
Pour améliorer encore la vitesse de réponse, nous avons choisi de réaliser les tests les plus rapides en premier et les tests lents en dernier (ils ne seront donc réalisés qu'en dernier recours).
Vous avez certainement déjà déduit à la lecture des propos précédents que nous allons vous proposer trois méthodes successives de contrôle des index.
IV. Initialisation des contrôles▲
Cette initialisation a lieu au sein de la méthode CIC_Contrôle_Phase_Init :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
C_POINTEUR($1) `on passe le champ indexé à contrôler
C_POINTEUR(cic_pField) `pointeur sur le champ à contrôler
C_POINTEUR(cic_pTable) `pointeur sur la table du champ à contrôler
C_ENTIER LONG(cic_error) `le code d'erreur (0=pas d'erreur)
C_TEXTE(cic_error_text) `le texte d'erreur
C_TEXTE(cic_info_text) `le texte d'information sur l'index
cic_pField:=$1
cic_pTable:=Table(Table(cic_pField))
cic_error:=0
cic_error_text:=""
cic_info_text:=""
Cette méthode initialise le code d'erreur cic_error et le texte associé cic_error_text. Une variable cic_info_text permettra de collationner des informations sur l'index au fil du traitement.
V. Première phase de contrôle▲
La première phase de contrôle permet de vérifier si le nombre d'éléments dans la sélection ne varie pas suite à un tri indexé. Voici le code de la méthode CIC_Controle_Phase_1 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
C_BOOLEEN($0)
C_ENTIER LONG($cic_RecordMax_in_table)
C_ENTIER LONG(cic_Record_in_selection)
C_ENTIER LONG(cic_Record_in_table)
`selection globale
TOUT SELECTIONNER(cic_pTable->)
ALLER A DERNIER ENREGISTREMENT(cic_pTable->)
$cic_RecordMax_in_table:=Numero enregistrement(cic_pTable->)
cic_Record_in_table:=Enregistrements dans table(cic_pTable->)
`initialisation de la bit table (utilisée en phase 3 et 4)
TABLEAU BOOLEEN($_bit_Table;$cic_RecordMax_in_table+1)
TABLEAU BOOLEEN(_cic_bit_Table;$cic_RecordMax_in_table+1)
COPIER TABLEAU($_bit_Table;_cic_bit_Table)
`tri indexé de la sélection
TRIER(cic_pTable->;cic_pField->)
`taille de la sélection après le tri
cic_Record_in_selection:=Enregistrements trouves(cic_pTable->)
Si (cic_Record_in_selection#cic_Record_in_table)
$0:=Vrai
cic_error:=1001
cic_error_text:="Il manque des clefs d'index ou des enregistrements."
Sinon
$0:=Faux
Fin de si
Pour que l'erreur 1001 soit détectée, il faut que le nombre d'enregistrements dans la sélection après le tri indexé soit différent du nombre d'enregistrements avant le tri. Ceci peut se produire dans les cas suivants :
- une clef d'index est perdue. La sélection issue du tri dépend de l'index est dans ce cas le nombre d'enregistrements après le tri sera inférieur au nombre avant le tri. Tester avec le fichier de données « NT_Index_manqueclef.4DD » ;
- un enregistrement est effacé sans que l'index soit mis à jour ; on a donc une clef en trop.
VI. Deuxième phase de contrôle▲
La deuxième phase de contrôle utilise la commande de 4D nommée VALEURS DISTINCTES. Lorsque l'index est disponible (c'est notre cas !), cette commande utilise l'index pour construire la liste des valeurs distinctes présentes au sein de ce dernier. Cette construction s'effectue par un balayage des pages d'index dans l'ordre afin de trouver les différentes valeurs. Le résultat fourni est un tableau ordonné des valeurs trouvées. Dans cette phase de contrôle, nous allons parcourir le tableau pour vérifier que l'ordre des éléments est bien correct. Voici le code de la méthode CIC_Controle_Phase_2 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
C_BOOLEEN($0)
C_ENTIER LONG($nb_erreur_comparaison)
C_ENTIER LONG($nb_val)
C_ENTIER LONG($cic_Field_Type)
TABLEAU TEXTE($_values_A;0)
TABLEAU REEL($_values_N;0)
TABLEAU DATE($_values_D;0)
TABLEAU ENTIER LONG($_values_H;0)
TABLEAU BOOLEEN($_values_B;0)
$cic_Field_Type:=Type(cic_pField->)
`%W-518.10
$nb_erreur_comparaison:=0
Au cas ou
: ($cic_Field_Type=Est un champ alpha) | ($cic_Field_Type=Est un texte )
VALEURS DISTINCTES(cic_pField->;$_values_A)
$nb_val:=Taille tableau($_values_A)
Si ($nb_val>1)
`%R-
Boucle ($i;2;$nb_val;1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_A{$i}<$_values_A{$i-1}))
Fin de boucle
Boucle ($i;$nb_val-1;1;-1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_A{$i}>$_values_A{$i+1}))
Fin de boucle
`%R+
Fin de si
: ($cic_Field_Type=Est un entier) | ($cic_Field_Type=Est un entier long) | ($cic_Field_Type=Est un numérique)
VALEURS DISTINCTES(cic_pField->;$_values_N)
$nb_val:=Taille tableau($_values_N)
Si ($nb_val>1)
`%R-
Boucle ($i;2;$nb_val;1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_N{$i}<$_values_N{$i-1}))
Fin de boucle
Boucle ($i;$nb_val-1;1;-1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_N{$i}>$_values_N{$i+1}))
Fin de boucle
`%R+
Fin de si
: ($cic_Field_Type=Est une date )
VALEURS DISTINCTES(cic_pField->;$_values_D)
$nb_val:=Taille tableau($_values_D)
Si ($nb_val>1)
`%R-
Boucle ($i;2;$nb_val;1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_D{$i}<$_values_D{$i-1}))
Fin de boucle
Boucle ($i;$nb_val-1;1;-1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_D{$i}>$_values_D{$i+1}))
Fin de boucle
`%R+
Fin de si
: ($cic_Field_Type=Est une heure)
VALEURS DISTINCTES(cic_pField->;$_values_H)
$nb_val:=Taille tableau($_values_H)
Si ($nb_val>1)
`%R-
Boucle ($i;2;$nb_val;1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_H{$i}<$_values_H{$i-1}))
Fin de boucle
Boucle ($i;$nb_val-1;1;-1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_H{$i}>$_values_H{$i+1}))
Fin de boucle
`%R+
Fin de si
: ($cic_Field_Type=Est un booléen )
VALEURS DISTINCTES(cic_pField->;$_values_B)
$nb_val:=Taille tableau($_values_B)
Si ($nb_val>1)
`%R-
Boucle ($i;2;$nb_val;1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_B{$i}<$_values_B{$i-1}))
Fin de boucle
Boucle ($i;$nb_val-1;1;-1)
$nb_erreur_comparaison:=$nb_erreur_comparaison+Num(($_values_B{$i}>$_values_B{$i+1}))
Fin de boucle
`%R+
Fin de si
Fin de cas
cic_info_text:=cic_info_text+Caractere(13)+"Il y a "+Chaine($nb_val)+" valeurs différentes dans l'index"
Si ($nb_erreur_comparaison=0)
$0:=Faux
Sinon
$0:=Vrai
cic_error:=1002
cic_error_text:="Erreur dans les valeurs distinctes : "+Chaine($nb_erreur_comparaison)+" comparaisons non valides"
Fin de si
Cette méthode teste le type du champ pour utiliser un type de tableau approprié. C'est indispensable en mode compilé où le retypage d'un tableau n'est pas possible, et c'est de toutes les manières, fortement recommandé en interprété !
Nous avons choisi de parcourir, grâce à deux boucles en sens opposés, le tableau : de cette manière chaque valeur est comparée à la précédente et à la suivante et aucune erreur ne peut nous échapper.
Afin d'augmenter la vitesse de calcul des boucles et comme notre code ne peut, grâce à sa construction, générer de dépassement de capacité, nous utilisons les instructions permettant de désactiver temporairement le contrôle d'exécution. C'est l'objet des instructions `%R- et `%R+.
Notre code utilise des pointeurs ce qui provoque des warnings lors de la compilation du code. Dans la méthode étudiée, nous avons les warnings suivants :
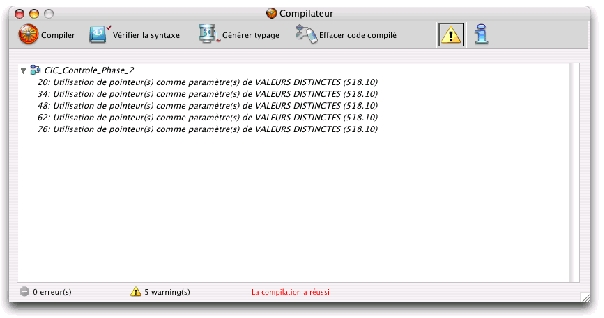
Les warnings générés sont normaux, car ce sont des avertissements qu'il faut comprendre de la manière suivante : « ici il y a un risque potentiel d'erreur lors de l'exécution en mode compilé ». Comme notre code respecte les règles de syntaxe et de retypage, nous n'aurons pas d'erreur et nous pouvons désactiver cette série de warnings. Comment faire ? Si nous utilisons le bouton de l'interface, nous désactivons tous les warnings et ne profitons pas éventuellement de l'aide proposée ailleurs. Si nous laissons les warnings actifs, ils vont revenir à chaque compilation et du coup nous ne voyons plus les alertes importantes.
La solution est de désactiver localement (c'est-à-dire méthode par méthode) chaque warning qui a été vérifié et validé. C'est l'objet de la ligne :
`%W-518.10
Cette ligne désactive pour la méthode le contrôle des warnings de type 518,10. Le type est indiqué entre parenthèses dans la fenêtre de compilation en regard de chaque warning.
Cette possibilité est une nouveauté de la version 2004, dont nous tirons parti dans cette note technique.
Pour tester cette deuxième phase, vous pouvez utiliser le fichier de données « NT_Index_ErreurClef.4DD ».
En utilisant ce fichier de données, vous constaterez, en traçant la méthode, que le tableau résultant de la commande 4D VALEURS DISTINCTES commence avec les valeurs suivantes :
AAAAAAAAAA
ABBAAAAAAA
AAAAAAAAAA
BBBBBBBBBBB
CCCCCCCCCCC
…
Ce tableau est trié suivant les clefs d'index ce qui montre bien que l'index a des problèmes !
VII. Troisième phase de contrôle▲
La troisième phase de contrôle est une phase où l'on contrôle l'ordre des valeurs pour les champs de la sélection qui est triée en s'appuyant sur l'index.
Pour vérifier l'ordre, nous chargeons les enregistrements les uns après les autres. Comme cela peut prendre pas mal de temps, nous travaillons par bloc de 1000 enregistrements. Ainsi dès qu'un bloc présente au moins une erreur, les tests s'arrêtent, car l'information est suffisante pour mettre en doute l'index (Erreur 1003).
Dans cette phase, les enregistrements doivent être chargés réellement ; nous passons donc la table concernée en mode lecture seule afin de ne pas verrouiller les enregistrements.
Nous profitons du balayage pour cumuler le nombre de valeurs ayant au moins un doublon dans un autre enregistrement. Par contre nous ne donnons le résultat que si les tests ont été menés à leur terme.
Enfin nous construisons un tableau booléen de la taille de la sélection. À chaque enregistrement lu, nous marquons la case qui correspond à son numéro en la passant à Vrai. Si par hasard la case était déjà marquée à Vrai, alors il y a une erreur dans la table d'adresse de la table, et nous la signalons (Erreur 1004). Nous utilisons pour cela le tableau _cic_bit_Table initialisé en phase 1.
Voici le code pour la troisième phase de contrôle :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
115.
116.
117.
118.
119.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
130.
131.
132.
133.
134.
135.
136.
137.
138.
139.
140.
141.
142.
143.
144.
145.
146.
147.
148.
149.
150.
151.
152.
153.
154.
155.
156.
157.
158.
159.
C_BOOLEEN($0)
C_TEXTE($cic_Previous_Value_A)
C_REEL($cic_Previous_Value_N)
C_DATE($cic_Previous_Value_D)
C_ENTIER LONG($cic_Previous_Value_H)
C_BOOLEEN($cic_Previous_Value_B)
C_ENTIER LONG($cic_Nb_valeur_identique)
C_ENTIER LONG($cic_Step_in_Selection)
C_ENTIER LONG($cic_Nb_valeur_identique)
C_ENTIER LONG($cic_Nb_error_comparaison)
C_BOOLEEN($lecture_seule)
TABLEAU TEXTE($_value_A;0)
TABLEAU REEL($_value_N;0)
TABLEAU DATE($_value_D;0)
TABLEAU ENTIER LONG($_value_H;0)
TABLEAU BOOLEEN($_value_B;0)
$cic_Field_Type:=Type(cic_pField->)
Au cas ou
: (cic_Record_in_table#cic_Record_in_selection)
$0:=Vrai
cic_error:=1001
cic_error_text:="Il manque des clefs d'index ou des enregistrements."
: (cic_Record_in_selection>1)
$cic_Step_in_Selection:=1
$lecture_seule:=Etat lecture seulement(cic_pTable->)
Si (Non($lecture_seule))
LECTURE SEULEMENT(cic_pTable->)
Fin de si
ALLER DANS SELECTION(cic_pTable->;$cic_Step_in_Selection)
Au cas ou
: ($cic_Field_Type=Est un champ alpha) | ($cic_Field_Type=Est un texte)
$cic_Previous_Value_A:=cic_pField->
$Previous_Value_A:=$cic_Previous_Value_A
$cic_Nb_valeur_identique:=Num(Numero enregistrement(cic_pTable->)=Trouver clef index(cic_pField->;$Previous_Value_A))
: ($cic_Field_Type=Est un entier) | ($cic_Field_Type=Est un entier long) | ($cic_Field_Type=Est un numérique)
$cic_Previous_Value_N:=cic_pField->
$Previous_Value_N:=$cic_Previous_Value_N
$cic_Nb_valeur_identique:=Num(Numero enregistrement(cic_pTable->)=Trouver clef index(cic_pField->;$Previous_Value_N))
: ($cic_Field_Type=Est une date )
$cic_Previous_Value_D:=cic_pField->
$Previous_Value_D:=$cic_Previous_Value_D
$cic_Nb_valeur_identique:=Num(Numero enregistrement(cic_pTable->)=Trouver clef index(cic_pField->;$Previous_Value_D))
: ($cic_Field_Type=Est une heure)
$cic_Previous_Value_H:=cic_pField->
$Previous_Value_H:=$cic_Previous_Value_H
$cic_Nb_valeur_identique:=Num(Numero enregistrement(cic_pTable->)=Trouver clef index(cic_pField->;$Previous_Value_H))
: ($cic_Field_Type=Est un booléen)
$cic_Previous_Value_B:=cic_pField->
$Previous_Value_B:=$cic_Previous_Value_B
$cic_Nb_valeur_identique:=Num(Numero enregistrement(cic_pTable->)=Trouver clef index(cic_pField->;$Previous_Value_B))
Fin de cas
_cic_bit_Table{Numero enregistrement(cic_pTable->)+1}:=Vrai
$cic_Nb_error_comparaison:=0
$cic_Nb_error_bit_table:=0
$nb_pas:=Arrondi(cic_Record_in_selection/1000;-2)
Si ($nb_pas>1000) | ($nb_pas<1)
$nb_pas:=1000
Fin de si
Boucle ($pas;1;cic_Record_in_selection;$nb_pas)
Boucle ($j;1;$nb_pas;1)
$cic_Step_in_Selection:=$cic_Step_in_Selection+1
Si ($cic_Step_in_Selection<=cic_Record_in_selection)
ALLER DANS SELECTION(cic_pTable->;$cic_Step_in_Selection)
$record_number:=Numero enregistrement(cic_pTable->)
$cic_Nb_error_bit_table:=$cic_Nb_error_bit_table+Num(_cic_bit_Table{$record_number+1})
_cic_bit_Table{$record_number+1}:=Vrai
Au cas ou
: ($cic_Field_Type=Est un champ alpha) | ($cic_Field_Type=Est un texte)
$value_A:=cic_pField->
$cic_Nb_error_comparaison:=$cic_Nb_error_comparaison+Num($value_A<$cic_Previous_Value_A)
$cic_Previous_Value_A:=$value_A
$cic_Nb_valeur_identique:=$cic_Nb_valeur_identique
+Num($record_number=Trouver clef index(cic_pField->;$value_A))
: ($cic_Field_Type=Est un entier) | ($cic_Field_Type=Est un entier long)
| ($cic_Field_Type=Est un numérique)
$value_N:=cic_pField->
$cic_Nb_error_comparaison:=$cic_Nb_error_comparaison+Num($value_N<$cic_Previous_Value_N)
$cic_Previous_Value_N:=$value_N
$cic_Nb_valeur_identique:=$cic_Nb_valeur_identique
+Num($record_number=Trouver clef index(cic_pField->;$value_N))
: ($cic_Field_Type=Est une date)
$value_D:=cic_pField->
$cic_Nb_error_comparaison:=$cic_Nb_error_comparaison+Num($value_D<$cic_Previous_Value_D)
$cic_Previous_Value_D:=$value_D
$cic_Nb_valeur_identique:=$cic_Nb_valeur_identique
+Num($record_number=Trouver clef index(cic_pField->;$value_D))
: ($cic_Field_Type=Est une heure)
$value_H:=cic_pField->
$cic_Nb_error_comparaison:=$cic_Nb_error_comparaison+Num($value_H<$cic_Previous_Value_H)
$cic_Previous_Value_H:=$value_H
$cic_Nb_valeur_identique:=$cic_Nb_valeur_identique
+Num($record_Number=Trouver clef index(cic_pField->;$value_H))
: ($cic_Field_Type=Est un booléen)
$value_B:=cic_pField->
$cic_Nb_error_comparaison:=$cic_Nb_error_comparaison+Num($value_B<$cic_Previous_Value_B)
$cic_Previous_Value_B:=$value_B
$cic_Nb_valeur_identique:=$cic_Nb_valeur_identique
+Num($record_number=Trouver clef index(cic_pField->;$value_B))
Fin de cas
Sinon
$j:=$nb_pas+1
Fin de si
Fin de boucle
Si ($cic_Nb_error_bit_table#0) | ($cic_Nb_error_comparaison#0)
$pas:=cic_Record_in_selection+1
Fin de si
Fin de boucle
Au cas ou
: ($cic_Nb_error_comparaison#0)
$0:=Vrai
cic_error:=1003
cic_error_text:="Il y a au moins "+Chaine($cic_Nb_error_comparaison)+" erreur de comparaison"
: ($cic_Nb_error_bit_table#0)
$0:=Vrai
cic_error:=1004
cic_error_text:="Il y a au moins "+Chaine($cic_Nb_error_bit_table)+" erreur dans la table d'adresse"
Sinon
cic_info_text:=cic_info_text+"Nb clefs d'index = "+Chaine($cic_Step_in_Selection-1)
+Caractere(Retour chariot )
$0:=Faux
Fin de cas
cic_info_text:=cic_info_text+"Nb valeurs ayant au moins un double : "
+Chaine($cic_Nb_valeur_identique)+Caractere(Retour chariot )
Si (Non($lecture_seule))
LECTURE ECRITURE(cic_pTable->)
Fin de si
Sinon
$0:=Faux
Fin de cas
Vous pouvez tester le fichier de données « NT_Index_ErreurVal.4DD » pour vérifier que la méthode trouve bien des erreurs !
VIII. Comment réparer ?▲
Lorsqu'une erreur est signalée, il faut la prendre en compte dès que possible. Il est nécessaire de réparer la base de données d'une part (via 4D Tools ou similaire), et de vérifier l'environnement d'exploitation d'autre part : disque dur et mémoire.
IX. Limitation▲
Il se peut que certaines erreurs passent au travers des fourches caudines des méthodes proposées. En effet il existe des cas que nos méthodes ne traitent pas par exemple une différence entre la case de la valeur dans l'enregistrement et la valeur dans l'index. Ce sont des cas a priori rares, il y a donc toutes les chances que les autres vérifications détectent d'autres problèmes. Donc il faut être conscient des limitations des méthodes, mais ne pas être trop inquiet, car, somme toute, la base de données 4D est solide !
X. Pour aller plus loin…▲
Afin d'automatiser les vérifications, vous pouvez inclure les méthodes dans un process dédié en procédure stockée sur votre serveur. Les rapports sont alors envoyés par email à l'administrateur de la base de données.
XI. Base exemple▲
Téléchargez la base exemple :
base exemple